GCP F5 deployment - Active -Active with config Sync
i want to deploy F5s in different Zones in GCP . reading the below Document . i want to deploy 2 F5s in 2 Zones . https://clouddocs.f5.com/cloud/public/v1/google/Google_configsync.html both F5s are behind the Google loadbalancer. Question - how will config Sync work . meaning will both F5s have the same virtual server ip address ? where can i download a template to configure the 2 F5s in Config Sync deployment.65Views0likes6Comments
Securing and Scaling Hybrid apps with F5 NGINX (Part 2)
If you attended a cybersecurity trade-show lately, you may have noticed the term “Zero Trust (ZT)” advertised on almost every booth. It may seem like most security companies are offering the same value proposition: ‘Securing apps with ZT’. Its commonality stems from the fact that ZT is a broad term that can span endless use cases. ZT is not a feature or capability, rather a philosophy embraced by IT security leaders based on the idea that all traffic entering and exiting a system is not trusted and must be scrutinized before passing through. Organizations are shifting to a zero-trust mindset due to the increased complexity of cyber-attacks. Perimeter based firewalls are no longer sufficient in securing digital resources. In Part 1 of our series, we configured NGINX Plus as an external load balancer to route and terminate TLS traffic to cluster nodes. In this part of the series, we leverage the same NGINX Plus deployment to enable ZT use cases that will improve the security posture of your hybrid applications. NOTE: Part 1 of the series is a prerequisite for enabling the ZT use cases in our examples. Please ensure that part 1 is completed before starting with part 2 Part 1 of the series ZT Use case #1: OIDC Authentication OIDC (OpenID Connect) is an authentication layer on top of the OAuth 2.0 framework. Many organizations will choose OIDC to authenticate digital identities and enable SSO (Single-Sign-On) for consumer applications. With Single-Sign-on technologies, users gain access to multiple applications with one set of user credentials by authenticating their identities through an IdP (Identity Provider). I can configure NGINX Plus to operate as an OIDC relaying party to exchange and validate ID tokens with the IdP (Identity Provider), in addition to basic reverse-proxy load balancing configured in part 1. I will extend the architecture in part 1 with an IdP and configure NGINX Plus as the identity aware proxy. Prerequisites for NGINX Plus Before configuring NGINX Plus as the OIDC identity aware proxy: 1. Installation of NJS is required. $ sudo apt-get install nginx-plus-module-njs 2. Load the NJS module into the NGINX configuration by adding the following line at the top of yournginx.conf file. load_module modules/ngx_http_js_module.so; 3. Clone the OIDC GitHub repository in your directory of choice cd /home/ubuntu && git clone --branch R28 https://github.com/nginxinc/nginx-openid-connect.git Setting up the IdP The IdP will manage and store digital identities to mitigate attackers from impersonating users to steal sensitive information. There are many IdP vendors to choose from; Okta, Ping Identity, Azure AD. We chose Okta as the IdP in our example moving forward. If you do not have access to an IdP, you can quickly get started with the Okta Command Line Interface (CLI) and run the okta register command to sign up for a new account. Once account creation is successful, we will use the Okta CLI to preconfigure Okta as the IdP, creating what Okta calls an app integration. Other IdPs will have different nomenclatures defining an application integration. For example, Azure AD will call them App registrations. If you are not using Okta, you can follow the documentation of the IdP you are using and skip to the next section (Configuring NGINX as the OpenID Connect relying party). 1. Run the okta login command to authenticate the Okta Cli with your Okta developer account. Enter your Okta domain and API token at the prompts $ okta login Okta Org URL: https://your-okta-domain Okta API token: your-api-token 2. Create the app integration $ okta apps create --app-name=mywebapp --redirect-uri=https://<nginx-plus-hostname>:443/_codexch where --app-name defines the application name (here, mywebapp) --redirect-uri defines the URI to which sign-ins are redirected to the NGINX Plus. <nginx-plus-hostname> should resolve to the NGINX Plus external IP configured in part 1. We use port 443 since TLS termination is configured on NGINX Plus from part 1. Recall we used self-signed certificates and keys to configure TLS on NGINX Plus. In a production environment, we recommend using certs/keys issued by a trusted certificate authority such as Let’s Encrypt. Once the command from step #2 is completed, the client ID and Secret generated from the app integration can be found in ${HOME}/.okta.env Configuring NGINX as the OpenID Connect relying party Now that we have finished setting up our IdP, we can now start configuring NGINX Plus as the OpenID Connect relying party. Once logged into the NGINX Plus instance, simply run the configuration script from your home directory. $ ./nginx-openid-connect/configure.sh -h <nginx-plus-hostname> -k request -i <YOURCLIENTID> -s <YOURCLIENTSECRET> –xhttps://dev-xxxxxxx.okta.com/.well-known/openid-configuration where -h defines the hostname of NGINX Plus -k defines how NGINX will retrieve JWK files to validate JWT signatures. The JWK file is retrieved from a subrequest to the IdP -i defines the Client ID generated from the IdP -s defines the Client Secret generated from the IdP -x defines the URL of the OpenID configuration endpoint. Using Okta as the example, the URL starts with your Okta organization domain, followed by the path URI /.well-known/openid-configuration The configure script will generate OIDC config files for NGINX Plus. We will copy the generated config files into the /etc/nginx/conf.d directory from part 1. $ sudo cp frontend.conf openid_connect.js openid_connect.server_conf openid_connect_configuration.conf /etc/nginx/conf.d/ You will notice by default that frontend.conf listens on port 8010 with clear text http. We need to merge kube_lb.conf into frontend.conf to enable both use cases from part 1 and 2. The resulting frontend.conf should look something like this: https://gist.github.com/nginx-gists/af067326734063da6a4ff42146873262 Finally, I will need to edit the openid_connect_configuration.conf file and modify my client secret to the one generated by my Okta IdP. Reload NGINX Plus for the new config to take effect. $ nginx -s reload Testing the Environment Now we are ready to test our environment in action. To summarize, we set up an IdP and configured NGINX Plus as the identity aware proxy to validate user ID tokens before the entering the Kubernetes cluster. To test the environment, we will open a browser and enter the hostname of NGINX Plus into the address field. You should be redirected to your IdP login page. Note: The host name should resolve to the Public IP of the NGINX Plus machine. Once you are prompted with the IdP login page from your browser, you can access the Kubernetes pods once the user credentials are validated. User credentials should be defined from the IdP. Once you are logged into your application, the ID token of the authenticated is stored in the NGINX Plus Key-Value Store. Enabling PKCE with OIDC In the previous section, we learned how to configure NGINX Plus as the OIDC relying party to authenticate user identities attempting connections to protected Kubernetes applications. However, there are few cases where attackers can intercept code exchange requests issued from the IdP and hijack your ID tokens and gain access to your sensitive applications. PKCE is an extension of the OIDC Authorization code flow designed to protect against authorization code interception and theft. PKCE provides an extra layer of security where the attacker will need to provide a code verifier in addition to the authorization code in exchange for the ID token from the IdP. In our current setup, NGINX Plus will send a random generated PKCE code verifier as a query parameter when redirecting users to the IdP login page. The IdP will use this PKCE code verifier as extra validation when the authorization code is exchanged for the ID token. PKCE needs to be enabled from both NGINX Plus and the IdP. To enable PKCE verification on NGINX Plus, edit the openid_connect_configuration.conf file and modify $oidc_pkce_enable to 1 and reload NGINX Plus. Depending on the IdP you are using, a checkbox should be available to enable PKCE. Testing the Environment To test that PKCE is working, we will open a browser and enter the NGINX Plus host name once again. You should be redirected to the login page, only this time you will notice the URL had slightly changed with additional query parameters: code_challenge_method – Method used to hash the plain code verifier (most likely SHA256) code_challenge – The hashed value of the plain code verifier NGINX Plus will provide this plain code verifier along with the authorization code in exchange for the ID token. NGINX Plus will then validate the ID token and store it in cache. Extending OIDC with 3rd party Systems Customers may need to integrate their OIDC workflow with proprietary Auth/Auth systems already in production. For example, additional metadata pertaining to a user may need to be collected from an external Redis Cache or JFrog Artifactory. We can fill this gap by extending our diagram from the previous section. In addition to token validation with NGINX Plus, I pull response data from JFrog Artifactory and pass it to the backend applications once users are authenticated. Note: I am using JFrog Artifactory as an example 3rd party endpoint here. I can technically use any endpoint I want. Testing the Environment To test our environment in action, I will make a few updates to my NGINX OIDC configuration. You can pull our updated GitHub repository and use it as reference for updating your NGINX configuration. Update #1: Adding the njs source code The first update is extending NGINX Plus with njs and retrieving response data from our 3rd party system. Add the KvOperations.js source file in your /etc/nginx/njs directory. Update #2: frontend.conf I am adding lines 37-39 to frontend.conf so that NGINX Plus will initiate the sub-request to our 3rd party system after users are authenticated with OIDC. We are setting the URI of this sub-request to /kvtest. More on this on the next update. Update #3: openid_connect.server_conf We are adding lines 35-48 to openid_connect.server_conf consisting of two internal redirects in NGINX: /kvtest; Internal redirect from sub-requests with URI /kvtest will functions in KvOperations.js /auth; Internal redirect for sub-requests with URI /authwill be proxied to the 3rd party endpoint. You can replace the <artifactory-url> in line 47 with your own endpoints Update #4: openid_connect_configuration.conf This update is optional and applies when passing dynamic variables to your 3rd party endpoints. You can dynamically update variables on the fly by sending POST requests to the NGINX Plus Key-Value store. $ curl -iX POST -d '{"admin", "<input-value>"}' http://localhost:9000/api/7/http/<keyval-zone-name> We are defining/instantiating the new Key-Value store in lines 102-104.Once the updates are complete, I can test the optimized OIDC environment by troubleshooting/verifying the application is on the receiving end of my dynamic input values. Wrapping it up I covered a subset of ZT use cases with NGINX in hybrid architectures. The use cases presented in this article center around authentication. In the next part of our series, I will cover more ZT use case that include: Alternative authentication methods (SAML) Encryption Authorization and Access Control Monitoring/Auditing110Views0likes0Comments
F5OS API is config save/commit needed?
Hi, there has been an option to save config at iControl Rest on classic F5s. How it is with F5OS API, do we have to save changes done by API to make them permanent/saved? It was POST to "/mgmt/tm/sys/config" with payload {"command": "save"} in the iControl Rest. Thanks40Views0likes2Comments
Inquiry on F5's Maintenance Mode Feature for Pool Members
Hello F5 Community, I'm looking for a way to smoothly transition specific pool members into maintenance mode without disrupting service. Can anyone share insights or best practices on how to implement this in our network infrastructure? Thanks!Solved105Views0likes11CommentsAS3 Deployments (shared objects)
BIG-IP LTM: 17.1.1 AS3 Plugin: 3.49.0 We are migrating from older hardware to newer r5900 series hardware. In that process we are moving to configuration as code, using AS3. Working through all the hiccups and hurdles, came across a "need", that I was wondering if possible?! Can you have a "global" (or "shared") partition with configurations within that all partitions can reference? I inherited the previous configurations from a colleague, and everything is located within the Common partition, which has kinda worked out nicely, as we can share "objects" (iRules, profiles, etc..) between most configurations. This also has been beneficial when we need to make a global change (certificate chain change, for example) that allowed us to fix all configurations quickly by changing just the one object that was shared. Is this possible across partitions, or is that a hard silo division, and nothing can be shared between them?Solved78Views0likes5Comments
HTTP Header Rewrite - X-Forwarded-Proto
Hi All, I have an issue wherein our client has added a new data source, which is traversing a load balancer before it reaches us. The clients Load Balancer is inserting X-Forwarded-Proto: HTTPS to the header. The Virtual Server on our side is also inserting X-Forwarded-Proto: HTTPS, which results in the header looking like this: X-Forwarded-Proto: https, https Our web servers are not happy with this and are dropping the traffic with a 403 error. Client have advised that they cannot fix this on their side, and we need to fix it on our side. I am reluctant to make any changes to working existing traffic, and we need the X-Forwarded-Proto: HTTPS My plan was to add an iRule to modify the headers to correct the error, but only for the source that's failing, identifying the traffic using the Client IP. Here is the iRule I was planning to use. Can anyone advise if this approach will work theoretically, and if my iRule looks correct? when HTTP_REQUEST { if {![class match [IP::client_addr] equals ip_group]} { HTTP::header replace "X-Forwarded-Proto" "https" } } Thanks in advance.32Views0likes2CommentsiRules Style Guide
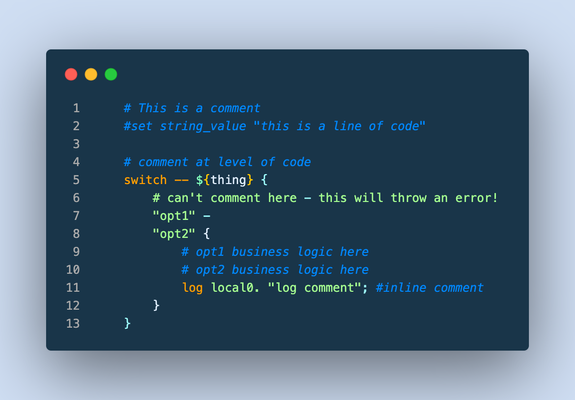
This article (formatted here in collaboration with and from the notes of F5er Jim_Deucker) features an opinionated way to write iRules, which is an extension to the Tcl language. Tcl has its own style guide for reference, as do other languages like my personal favorite python. From the latter, Guido van Rossum quotes Ralph Waldo Emerson: "A foolish consistency is the hobgoblin of little minds..," or if you prefer, Morpheus from the Matrix: "What you must learn is that these rules are no different than the rules of a computer system. Some of them can be bent. Others can be broken." The point? This is a guide, and if there is a good reason to break a rule...by all means break it! Editor Settings Setting a standard is good for many reasons. It's easier to share code amongst colleagues, peers, or the larger community when code is consistent and professional looking. Settings for some tools are provided below, but if you're using other tools, here's the goal: indent 4 spaces (no tab characters) 100-column goal for line length (120 if you must) but avoid line continuations where possible file parameters ASCII Unix linefeeds (\n) trailing whitespace trimmed from the end of each line file ends with a linefeed Visual Studio Code If you aren't using VSCode, why the heck not? This tool is amazing, and with the F5 Networks iRules extension coupled with The F5 Extension, you get the functionality of a powerful editor along with the connectivity control of your F5 hosts. With code diagnostics and auto formatting based on this very guide, the F5 Networks iRules Extension will make your life easy. Seriously...stop reading and go set up VSCode now. EditorConfig For those with different tastes in text editing using an editor that supports EditorConfig: # 4 space indentation [*.{irule,irul}] indent_style = space indent_size = 4 end_of_line = lf insert_final_newline = true charset = ascii trim_trailing_whitespace = true Vim I'm a vi guy with sys-admin work, but I prefer a full-fledge IDE for development efforts. If you prefer the file editor, however, we've got you covered with these Vim settings: # in ~/.vimrc file set tabstop=4 set shiftwidth=4 set expandtab set fileencoding=ascii set fileformat=unix Sublime There are a couple tools for sublime, but all of them are a bit dated and might require some work to bring them up to speed. Unless you're already a Sublime apologist, I'd choose one of the other two options above. sublime-f5-irules (bitwisecook fork, billchurch origin) for editing Sublime Highlight for export to RTF/HTML Guidance Watch out for smart-quotes and non-breaking spaces inserted by applications like Microsoft Word as they can silently break code. The VSCode extension will highlight these occurrences and offer a fix automatically, so again, jump on that bandwagon! A single iRule has a 64KB limit. If you're reaching that limit it might be time to question your life choices, I mean, the wisdom of the solution. Break out your iRules into functional blocks. Try to separate (where possible) security from app functionality from stats from protocol nuances from mgmt access, etc. For example, when the DevCentral team managed the DevCentral servers and infrastructure, we had 13 iRules to handle maintenance pages, masking application error codes and data, inserting scripts for analytics, managing vanity links and other structural rewrites to name a few. With this strategy, priorities for your events are definitely your friend. Standardize on "{" placement at the end of a line and not the following line, this causes the least problems across all the BIG-IP versions. # ### THIS ### if { thing } { script } else { other_script } # ### NOT THIS ### if { thing } { script } else { other_script } 4-character indent carried into nested values as well, like in switch. # ### THIS ### switch -- ${thing} { "opt1" { command } default { command } } Comments (as image for this one to preserve line numbers) Always comment at the same indent-level as the code (lines 1, 4, 9-10) Avoid end-of-line comments (line 11) Always hash-space a comment (lines 1, 4, 9-10) Leave out the space when commenting out code (line 2) switch statements cannot have comments inline with options (line 6) Avoid multiple commands on a single line. # ### THIS ### set host [getfield [HTTP::host] 1] set port [getfield [HTTP::host] 2] # ### NOT THIS ### set host [getfield [HTTP::host] 1]; set port [getfield [HTTP::host] 2] Avoid single-line if statements, even for debug logs. # ### THIS ### if { ${debug} } { log local0. "a thing happened...." } # ### NOT THIS ### if { ${debug} } { log local0. "a thing happened..."} Even though Tcl allows a horrific number of ways to communicate truthiness, Always express or store state as 0 or 1 # ### THIS ### set f 0 set t 1 if { ${f} && ${t} } { ... } # ### NOT THIS ### # Valid false values set f_values "n no f fal fals false of off" # Valid true values set t_values "y ye yes t tr tru true on" # Set a single valid, but unpreferred, state set f [lindex ${f_values} [expr {int(rand()*[llength ${f_values}])}]] set t [lindex ${t_values} [expr {int(rand()*[llength ${t_values}])}]] if { ${f} && ${t} } { ... } Always use Tcl standard || and && boolean operators over the F5 special and and or operators in expressions, and use parentheses when you have multiple arguments to be explicitly clear on operations. # ### THIS ### if { ${state_active} && ${level_gold} } { if { (${state} == "IL") || (${state} == "MO") } { pool gold_pool } } # ### NOT THIS ### if { ${state_active} and ${level_gold} } { if { ${state} eq "IL" or ${state} eq "MO" } { pool gold_pool } } Always put a space between a closing curly bracket and an opening one. # ### THIS ### if { ${foo} } { log local0.info "something" } # ### NOT THIS ### if { ${foo} }{ log local0.info "something" } Always wrap expressions in curly brackets to avoid double expansion. (Check out a deep dive on the byte code between the two approaches shown in the picture below) # ### THIS ### set result [expr {3 * 4}] # ### NOT THIS ### set result [expr 3 * 4] Always use space separation around variables in expressions such as if statements or expr calls. Always wrap your variables in curly brackets when referencing them as well. # ### THIS ### if { ${host} } { # ### NOT THIS ### if { $host } { Terminate options on commands like switch and table with "--" to avoid argument injection if if you're 100% sure you don't need them. The VSCode iRules extension will throw diagnostics for this. SeeK15650046 for more details on the security exposure. # ### THIS ### switch -- [whereis [IP::client_addr] country] { "US" { table delete -subtable states -- ${state} } } # ### NOT THIS ### switch [whereis [IP::client_addr] country] { "US" { table delete -subtable states ${state} } } Always use a priority on an event, even if you're 100% sure you don't need them. The default is 500 so use that if you have no other starting point. Always put a timeout and/or lifetime on table contents. Make sure you really need the table space before settling on that solution, and consider abusing the static:: namespace instead. Avoid unexpected scope creep with static:: and table variables by assigning prefixes. Lacking a prefix means if multiple rules set or use the variable changing them becomes a race condition on load or rule update. when RULE_INIT priority 500 { # ### THIS ### set static::appname_confvar 1 # ### NOT THIS ### set static::confvar 1 } Avoid using static:: for things like debug configurations, it's a leading cause of unintentional log storms and performance hits. If you have to use them for a provable performance reason follow the prefix naming rule. # ### THIS ### when CLIENT_ACCEPTED priority 500 { set debug 1 } when HTTP_REQUEST priority 500 { if { ${debug} } { log local0.debug "some debug message" } } # ### NOT THIS ### when RULE_INIT priority 500 { set static::debug 1 } when HTTP_REQUEST priority 500 { if { ${static::debug} } { log local0.debug "some debug message" } } Comments are fine and encouraged, but don't leave commented-out code in the final version. Wrapping up that guidance with a final iRule putting it all into practice: when HTTP_REQUEST priority 500 { # block level comments with leading space #command commented out if { ${a} } { command } if { !${a} } { command } elseif { ${b} > 2 || ${c} < 3 } { command } else { command } switch -- ${b} { "thing1" - "thing2" { # thing1 and thing2 business reason } "thing3" { # something else } default { # default branch } } # make precedence explicit with parentheses set d [expr { (3 + ${c} ) / 4 }] foreach { f } ${e} { # always braces around the lists } foreach { g h i } { j k l m n o p q r } { # so the lists are easy to add to } for { set i 0 } { ${i} < 10 } { incr i } { # clarity of each parameter is good } } What standards do you follow for your iRules coding styles? Drop a comment below!6.5KViews22likes12Comments
iRule interpretation assistance
Hi Dev Central. I need some assistance interpreting the following iRule, especially the first line. My interpretation is that if the HTTP path contains any of the following: /, /index.jsp, /startpage, /sap/admin, /sap/admin* AND the client IP address is NOT in the All-Internal_dg Data Group List, then the request is REJECTED. Is this correct? What is bothering me is the very first line with the "/". This would mean that any path would be rejected if the request isnt coming from an IP in the All-Internal_dg Data Group List right? I ask because this service is still accessible from IPs that are not in the All-Internal_dg Data Group List. So I am wondering how some paths are still working for clients that are not in the All-Internal_dg Data Group. Thanks for any help you can lend. switch -glob [HTTP::path] { "/" { # log 10.x.x.58 local0. "In root client ip is [IP::client_addr]" if { not [matchclass [IP::client_addr] equals All-Internal_dg] } { reject } HTTP::redirect https://[getfield [HTTP::host] ":" 1 ]/startPage } "/index.jsp" { # log 10..x.x.58 local0. "In index.jsp client ip is [IP::client_addr]" if { not [matchclass [IP::client_addr] equals All-Internal_dg] } { reject } HTTP::redirect https://[getfield [HTTP::host] ":" 1 ]/startPage } "/startpage" { # log 10.x.x.58 local0. "In startpage client ip is [IP::client_addr]" if { not [matchclass [IP::client_addr] equals All-Internal_dg] } { reject } } "/sap/admin" { # log 10..x.x.58 local0. "In sap admin client ip is [IP::client_addr]" if { not [matchclass [IP::client_addr] equals All-Internal_dg] } { reject } HTTP::redirect https://[getfield [HTTP::host] ":" 1 ]/sap/admin/public/default.html } "/sap/admin*" { # log 10..x.x.58 local0. "Deep in sap admin client ip is [IP::client_addr]" if { not [matchclass [IP::client_addr] equals All-Internal_dg] } { reject } } default { # log 10..x.x.58 local0. "Something hit the default switch client ip is [IP::client_addr]" } } }Solved45Views0likes6CommentsiCR Python Module for iControl REST
Problem this snippet solves: This is a python module to simplify using iControl REST. Install using pip: pip install iCR or retrieve from https://pypi.python.org/pypi?:action=display&name=iCR&version=2.1 As simple as: #!/usr/bin/env python from iCR import iCR bigip = iCR("172.24.9.132","admin","admin") virtuals = bigip.get("ltm/virtual") for vs in virtuals['items']: print vs['name'] This prints out a list of Virtual Servers. Supported methods: init(hostname,username,password,[timeout,port,icontrol_version,folder,token,debug]) get(url,[select,top,skip,filter]) -> returns data or False getlarge(url,size,[select]) -> Used to retrieve large datasets in chunks. Returns data or False create(url,data) -> returns data or False modify(url,data,[patch=True]) -> returns data or False delete(url) -> returns True or False upload(file) -> file is a local file eg /var/tmp/test.txt, returns True or False download(file) -> files are located in /shared/images, returns True or False create_cert(files) -> files is an array containing paths to cert and key. Returns name of cert or False get_asm_id(name) -> name is the name of a policy. Returns an array of IDs or False create_hash(name) -> name is the name of the partition and policy. eg /Common/test_policy. This reduces the need to retrieve an array of hashes from the BIG-IP. Returns a string. get_token() -> this retrieves a BIG-IP token based on the username and password and sets it as the token in use. Returns the token ID or False delete_token() -> This deletes the object token from the BIG-IP and from the object create_transaction() -> creates a transaction and returns the transaction number ID as a string, or False. Subsequent requests will be added to thetransaction until commit_transaction is called. Transaction ID is stored in object.transaction commit_transaction() -> Commits the transaction stored in object.transaction. Returns True or False command(args,[cmd]) -> Runs a command using the arguments string args. Returns the returned output or True on success or False on failure. Note:Be sure to double-escape single quotes eg \\' and single escape double quotes eg \" cmd options are ping/save/load/restart/reboot Module Variables: icr_session - the link to the requests session raw - the raw returned JSON code - the returned HTTP Status Code eg 200 error - in the case of error, the exception error string headers - the response headers icontrol_version - set this to specify a specific version of iControl debug - boolean True or False to set debugging on or off port - set the port ( 443 by default ) folder - set this to create in a specific partition token - use this to set a specific token. If this is set, it will be used instead of basic auth select - use this with get to select the returned data top - use this with get to return a set number of records skip - use this to skip to a specific record number transaction - stores the Transaction ID How to use this snippet: Examples Setup a REST connection to a device #!/usr/bin/env python from iCR import iCR bigip = iCR("172.24.9.132","admin","admin",timeout=10) Create a Virtual Server vs_config = {'name':'test_vs'} createvs = bigip.create("ltm/virtual",vs_config,timeout=5) Retrieve the VS we just created virt = bigip.get("ltm/virtual/test_vs",select="name") print "Virtual Server created: " + virt['name'] Set the timeout bigip.timeout = 20 Now delete the VS we just created delvs = bigip.delete("ltm/virtual/test_vs") Retrieve ASM policy to ID mapping policies = bigip.get("asm/policies",select="name,id") Print a table of ASM policies with learning mode print print "Policy Name Learning Mode" print "------------------------------------------" for item in policies['items']: enabled = bigip.get("asm/policies/" + item['id'] + "/policy-builder",select="learningMode") print '{:32}'.format(item['name']) + enabled['learningMode'] File upload fp = "/home/pwhite/input.csv" if bigip.upload(fp): print "File " + fp + " uploaded" File download file="BIGIP-12.1.2.0.0.249.iso" download = bigip.download(file) if not download: print "File " + file + " download error" SSL Certificate creation In different folder bigip.folder = "TestFolder" files = ("TestCert.crt","TestCert.key") cert = bigip.create_cert(files) if cert: print "Certificate " + cert + " created" Turn on debugging bigip.debug = True Retrieve ASM policy IDs asm = bigip.get_asm_id("dummy_policy") print len(asm) + " IDs returned" print "ID: " + str(asm[0]) Convert an ASM policy name to hash hash = bigip.create_hash("/Common/test-policy") enabled = bigip.get("asm/policies/" + hash + "/policy-builder",select="learningMode") print '{:32}'.format(item['name']) + enabled['learningMode'] Retrieve and use a token bigip.get_token() Delete the token bigip.delete_token() Developed on Python 2.7 but works with v3. Works on TMOS 11.6 onwards though some features may not be implemented, such as tokens. If you use this and have found bugs, would like to discuss it or suggest features then please PM me on DevCentral. Tested this on version: 13.01.1KViews0likes19CommentsF5 not sending traffic to Web pool
Hello All, I am having issues with a new configured F5 big-IP that everything works fine as follows. traffic from the client is coming to the firewall which is then natted to the private network. (works) the Load balancer ( Virtual server) IP is accessible and request is sent to the virtual server. and from the big ip to the pool is not sent. connection between the F5 to the pool is fine and vice versa and pool and nodes are available (green). connection between web-server and F5 is through Https (443). configuration F5 as follows: F5 Virtual IP : 192.168.1.41 self IP: int 1 : 10.10.10.14 self IP int 2 : 192.168.1.41 web server pool : 10.10.10.X range with class c subnet. SSL is configured between the client to F5 as clientssl and between the server and F5 as serverssl. source address translation is automap. I am having trouble why it doesn't work and is trying to find out the problem.97Views0likes8Comments