BIG-IP Configuration Conversion Scripts
Kirk Bauer, John Alam, and Pete White created a handful of perl and/or python scripts aimed at easing your migration from some of the “other guys” to BIG-IP.While they aren’t going to map every nook and cranny of the configurations to a BIG-IP feature, they will get you well along the way, taking out as much of the human error element as possible.Links to the codeshare articles below. Cisco ACE (perl) Cisco ACE via tmsh (perl) Cisco ACE (python) Cisco CSS (perl) Cisco CSS via tmsh (perl) Cisco CSM (perl) Citrix Netscaler (perl) Radware via tmsh (perl) Radware (python)1.6KViews1like13Comments
F5 Predicts: Education gets personal
The topic of education is taking centre stage today like never before. I think we can all agree that education has come a long way from the days where students and teachers were confined to a classroom with a chalkboard. Technology now underpins virtually every sector and education is no exception. The Internet is now the principal enabling mechanism by which students assemble, spread ideas and sow economic opportunities. Education data has become a hot topic in a quest to transform the manner in which students learn. According to Steven Ross, a professor at the Centre for Research and Reform in Education at Johns Hopkins University, the use of data to customise education for students will be the key driver for learning in the future[1].This technological revolution has resulted in a surge of online learning courses accessible to anyone with a smart device. A two-year assessment of the massive open online courses (MOOCs) created by HarvardX and MITxrevealed that there were 1.7 million course entries in the 68 MOOC [2].This translates to about 1 million unique participants, who on average engage with 1.7 courses each. This equity of education is undoubtedly providing vast opportunities for students around the globe and improving their access to education. With more than half a million apps to choose from on different platforms such as the iOS and Android, both teachers and students can obtain digital resources on any subject. As education progresses in the digital era, here are some considerations for educational institutions to consider: Scale and security The emergence of a smogasborad of MOOC providers, such as Coursera and edX, have challenged the traditional, geographical and technological boundaries of education today. Digital learning will continue to grow driving the demand for seamless and user friendly learning environments. In addition, technological advancements in education offers new opportunities for government and enterprises. It will be most effective if provided these organisations have the ability to rapidly scale and adapt to an all new digital world – having information services easily available, accessible and secured. Many educational institutions have just as many users as those in large multinational corporations and are faced with the issue of scale when delivering applications. The aim now is no longer about how to get fast connection for students, but how quickly content can be provisioned and served and how seamless the user experience can be. No longer can traditional methods provide our customers with the horizontal scaling needed. They require an intelligent and flexible framework to deploy and manage applications and resources. Hence, having an application-centric infrastructure in place to accelerate the roll-out of curriculum to its user base, is critical in addition to securing user access and traffic in the overall environment. Ensuring connectivity We live in a Gen-Y world that demands a high level of convenience and speed from practically everyone and anything. This demand for convenience has brought about reform and revolutionised the way education is delivered to students. Furthermore, the Internet of things (IoT), has introduced a whole new raft of ways in which teachers can educate their students. Whether teaching and learning is via connected devices such as a Smart Board or iPad, seamless access to data and content have never been more pertinent than now. With the increasing reliance on Internet bandwidth, textbooks are no longer the primary means of educating, given that students are becoming more web oriented. The shift helps educational institutes to better personalise the curriculum based on data garnered from students and their work. Duty of care As the cloud continues to test and transform the realms of education around the world, educational institutions are opting for a centralised services model, where they can easily select the services they want delivered to students to enhance their learning experience. Hence, educational institutions have a duty of care around the type of content accessed and how it is obtained by students. They can enforce acceptable use policies by only delivering content that is useful to the curriculum, with strong user identification and access policies in place. By securing the app, malware and viruses can be mitigated from the institute’s environment. From an outbound perspective, educators can be assured that students are only getting the content they are meant to get access to. F5 has the answer BIG-IP LTM acts as the bedrock for educational organisations to provision, optimise and deliver its services. It provides the ability to publish applications out to the Internet in a quickly and timely manner within a controlled and secured environment. F5 crucially provides both the performance and the horizontal scaling required to meet the highest levels of throughput. At the same time, BIG-IP APM provides schools with the ability to leverage virtual desktop infrastructure (VDI) applications downstream, scale up and down and not have to install costly VDI gateways on site, whilst centralising the security decisions that come with it. As part of this, custom iApps can be developed to rapidly and consistently deliver, as well as reconfigure the applications that are published out to the Internet in a secure, seamless and manageable way. BIG-IP Application Security Manager (ASM) provides an application layer security to protect vital educational assets, as well as the applications and content being continuously published. ASM allows educational institutes to tailor security profiles that fit like a glove to wrap seamlessly around every application. It also gives a level of assurance that all applications are delivered in a secure manner. Education tomorrow It is hard not to feel the profound impact that technology has on education. Technology in the digital era has created a new level of personalised learning. The time is ripe for the digitisation of education, but the integrity of the process demands the presence of technology being at the forefront, so as to ensure the security, scalability and delivery of content and data. The equity of education that technology offers, helps with addressing factors such as access to education, language, affordability, distance, and equality. Furthermore, it eliminates geographical boundaries by enabling the mass delivery of quality education with the right policies in place. [1] http://www.wsj.com/articles/SB10001424052702304756104579451241225610478 [2] http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2586847843Views0likes3Comments
5 Years Later: OpenAJAX Who?
Five years ago the OpenAjax Alliance was founded with the intention of providing interoperability between what was quickly becoming a morass of AJAX-based libraries and APIs. Where is it today, and why has it failed to achieve more prominence? I stumbled recently over a nearly five year old article I wrote in 2006 for Network Computing on the OpenAjax initiative. Remember, AJAX and Web 2.0 were just coming of age then, and mentions of Web 2.0 or AJAX were much like that of “cloud” today. You couldn’t turn around without hearing someone promoting their solution by associating with Web 2.0 or AJAX. After reading the opening paragraph I remembered clearly writing the article and being skeptical, even then, of what impact such an alliance would have on the industry. Being a developer by trade I’m well aware of how impactful “standards” and “specifications” really are in the real world, but the problem – interoperability across a growing field of JavaScript libraries – seemed at the time real and imminent, so there was a need for someone to address it before it completely got out of hand. With the OpenAjax Alliance comes the possibility for a unified language, as well as a set of APIs, on which developers could easily implement dynamic Web applications. A unified toolkit would offer consistency in a market that has myriad Ajax-based technologies in play, providing the enterprise with a broader pool of developers able to offer long term support for applications and a stable base on which to build applications. As is the case with many fledgling technologies, one toolkit will become the standard—whether through a standards body or by de facto adoption—and Dojo is one of the favored entrants in the race to become that standard. -- AJAX-based Dojo Toolkit , Network Computing, Oct 2006 The goal was simple: interoperability. The way in which the alliance went about achieving that goal, however, may have something to do with its lackluster performance lo these past five years and its descent into obscurity. 5 YEAR ACCOMPLISHMENTS of the OPENAJAX ALLIANCE The OpenAjax Alliance members have not been idle. They have published several very complete and well-defined specifications including one “industry standard”: OpenAjax Metadata. OpenAjax Hub The OpenAjax Hub is a set of standard JavaScript functionality defined by the OpenAjax Alliance that addresses key interoperability and security issues that arise when multiple Ajax libraries and/or components are used within the same web page. (OpenAjax Hub 2.0 Specification) OpenAjax Metadata OpenAjax Metadata represents a set of industry-standard metadata defined by the OpenAjax Alliance that enhances interoperability across Ajax toolkits and Ajax products (OpenAjax Metadata 1.0 Specification) OpenAjax Metadata defines Ajax industry standards for an XML format that describes the JavaScript APIs and widgets found within Ajax toolkits. (OpenAjax Alliance Recent News) It is interesting to see the calling out of XML as the format of choice on the OpenAjax Metadata (OAM) specification given the recent rise to ascendancy of JSON as the preferred format for developers for APIs. Granted, when the alliance was formed XML was all the rage and it was believed it would be the dominant format for quite some time given the popularity of similar technological models such as SOA, but still – the reliance on XML while the plurality of developers race to JSON may provide some insight on why OpenAjax has received very little notice since its inception. Ignoring the XML factor (which undoubtedly is a fairly impactful one) there is still the matter of how the alliance chose to address run-time interoperability with OpenAjax Hub (OAH) – a hub. A publish-subscribe hub, to be more precise, in which OAH mediates for various toolkits on the same page. Don summed it up nicely during a discussion on the topic: it’s page-level integration. This is a very different approach to the problem than it first appeared the alliance would take. The article on the alliance and its intended purpose five years ago clearly indicate where I thought this was going – and where it should go: an industry standard model and/or set of APIs to which other toolkit developers would design and write such that the interface (the method calls) would be unified across all toolkits while the implementation would remain whatever the toolkit designers desired. I was clearly under the influence of SOA and its decouple everything premise. Come to think of it, I still am, because interoperability assumes such a model – always has, likely always will. Even in the network, at the IP layer, we have standardized interfaces with vendor implementation being decoupled and completely different at the code base. An Ethernet header is always in a specified format, and it is that standardized interface that makes the Net go over, under, around and through the various routers and switches and components that make up the Internets with alacrity. Routing problems today are caused by human error in configuration or failure – never incompatibility in form or function. Neither specification has really taken that direction. OAM – as previously noted – standardizes on XML and is primarily used to describe APIs and components - it isn’t an API or model itself. The Alliance wiki describes the specification: “The primary target consumers of OpenAjax Metadata 1.0 are software products, particularly Web page developer tools targeting Ajax developers.” Very few software products have implemented support for OAM. IBM, a key player in the Alliance, leverages the OpenAjax Hub for secure mashup development and also implements OAM in several of its products, including Rational Application Developer (RAD) and IBM Mashup Center. Eclipse also includes support for OAM, as does Adobe Dreamweaver CS4. The IDE working group has developed an open source set of tools based on OAM, but what appears to be missing is adoption of OAM by producers of favored toolkits such as jQuery, Prototype and MooTools. Doing so would certainly make development of AJAX-based applications within development environments much simpler and more consistent, but it does not appear to gaining widespread support or mindshare despite IBM’s efforts. The focus of the OpenAjax interoperability efforts appears to be on a hub / integration method of interoperability, one that is certainly not in line with reality. While certainly developers may at times combine JavaScript libraries to build the rich, interactive interfaces demanded by consumers of a Web 2.0 application, this is the exception and not the rule and the pub/sub basis of OpenAjax which implements a secondary event-driven framework seems overkill. Conflicts between libraries, performance issues with load-times dragged down by the inclusion of multiple files and simplicity tend to drive developers to a single library when possible (which is most of the time). It appears, simply, that the OpenAJAX Alliance – driven perhaps by active members for whom solutions providing integration and hub-based interoperability is typical (IBM, BEA (now Oracle), Microsoft and other enterprise heavyweights – has chosen a target in another field; one on which developers today are just not playing. It appears OpenAjax tried to bring an enterprise application integration (EAI) solution to a problem that didn’t – and likely won’t ever – exist. So it’s no surprise to discover that references to and activity from OpenAjax are nearly zero since 2009. Given the statistics showing the rise of JQuery – both as a percentage of site usage and developer usage – to the top of the JavaScript library heap, it appears that at least the prediction that “one toolkit will become the standard—whether through a standards body or by de facto adoption” was accurate. Of course, since that’s always the way it works in technology, it was kind of a sure bet, wasn’t it? WHY INFRASTRUCTURE SERVICE PROVIDERS and VENDORS CARE ABOUT DEVELOPER STANDARDS You might notice in the list of members of the OpenAJAX alliance several infrastructure vendors. Folks who produce application delivery controllers, switches and routers and security-focused solutions. This is not uncommon nor should it seem odd to the casual observer. All data flows, ultimately, through the network and thus, every component that might need to act in some way upon that data needs to be aware of and knowledgeable regarding the methods used by developers to perform such data exchanges. In the age of hyper-scalability and über security, it behooves infrastructure vendors – and increasingly cloud computing providers that offer infrastructure services – to be very aware of the methods and toolkits being used by developers to build applications. Applying security policies to JSON-encoded data, for example, requires very different techniques and skills than would be the case for XML-formatted data. AJAX-based applications, a.k.a. Web 2.0, requires different scalability patterns to achieve maximum performance and utilization of resources than is the case for traditional form-based, HTML applications. The type of content as well as the usage patterns for applications can dramatically impact the application delivery policies necessary to achieve operational and business objectives for that application. As developers standardize through selection and implementation of toolkits, vendors and providers can then begin to focus solutions specifically for those choices. Templates and policies geared toward optimizing and accelerating JQuery, for example, is possible and probable. Being able to provide pre-developed and tested security profiles specifically for JQuery, for example, reduces the time to deploy such applications in a production environment by eliminating the test and tweak cycle that occurs when applications are tossed over the wall to operations by developers. For example, the jQuery.ajax() documentation states: By default, Ajax requests are sent using the GET HTTP method. If the POST method is required, the method can be specified by setting a value for the type option. This option affects how the contents of the data option are sent to the server. POST data will always be transmitted to the server using UTF-8 charset, per the W3C XMLHTTPRequest standard. The data option can contain either a query string of the form key1=value1&key2=value2 , or a map of the form {key1: 'value1', key2: 'value2'} . If the latter form is used, the data is converted into a query string using jQuery.param() before it is sent. This processing can be circumvented by setting processData to false . The processing might be undesirable if you wish to send an XML object to the server; in this case, change the contentType option from application/x-www-form-urlencoded to a more appropriate MIME type. Web application firewalls that may be configured to detect exploitation of such data – attempts at SQL injection, for example – must be able to parse this data in order to make a determination regarding the legitimacy of the input. Similarly, application delivery controllers and load balancing services configured to perform application layer switching based on data values or submission URI will also need to be able to parse and act upon that data. That requires an understanding of how jQuery formats its data and what to expect, such that it can be parsed, interpreted and processed. By understanding jQuery – and other developer toolkits and standards used to exchange data – infrastructure service providers and vendors can more readily provide security and delivery policies tailored to those formats natively, which greatly reduces the impact of intermediate processing on performance while ensuring the secure, healthy delivery of applications. API Jabberwocky: You Say Tomay-to and I Say Potah-to OpenAjax Metadata 1.0 and the Adobe Dreamweaver Widget Browser OpenAjax Alliance AJAX-based Dojo Toolkit The Stealthy Ascendancy of JSON JSON Continues its Winning Streak Over XML JSON versus XML: Your Choice Matters More Than You Think I am in your HTTP headers, attacking your application The Web 2.0 API: From collaborating to compromised IT as a Service: A Stateless Infrastructure Architecture Model JSON Activity Streams and the Other Consumerization of IT348Views0likes0Comments
APM Cookbook: Monitoring APM
I have a customer who recently needed to monitor the APM logon page but noticed the default HTTP monitor was eating up APM access sessions. To address this issue we need the HTTP monitor to retain the MRHSession cookie as it follows the redirect from / to /my.policy. After the monitor determines the health of the APM logon page it needs to also access the logout page to delete it's current access session. To accomplish this we can use the cookie jar option in curl: -c create the cookie jar -b uses an existing cookie jar We also tell curl to follow redirects with the -L argument. In the example code below the monitor is looking for the F5 licensing statement at the bottom of the APM logon page. If you've customized the APM logon page this monitor can easily be modified to fit your specific requirements. #!/bin/sh # # (c) Copyright 1996-2014 F5 Networks, Inc. # # This software is confidential and may contain trade secrets that are the # property of F5 Networks, Inc. No part of the software may be disclosed # to other parties without the express written consent of F5 Networks, Inc. # It is against the law to copy the software. No part of the software may # be reproduced, transmitted, or distributed in any form or by any means, # electronic or mechanical, including photocopying, recording, or information # storage and retrieval systems, for any purpose without the express written # permission of F5 Networks, Inc. Our services are only available for legal # users of the program, for instance in the event that we extend our services # by offering the updating of files via the Internet. # # @(#) $Id: http_monitor_cURL+GET,v 1.0 2007/06/28 16:10:15 deb Exp $ # (based on sample_monitor,v 1.3 2005/02/04 18:47:17 saxon) # # these arguments supplied automatically for all external monitors: # $1 = IP (IPv6 notation. IPv4 addresses are passed in the form # ::ffff:w.x.y.z # where "w.x.y.z" is the IPv4 address) # $2 = port (decimal, host byte order) # # remove IPv6/IPv4 compatibility prefix (LTM passes addresses in IPv6 format) IP=`echo ${1} | sed 's/::ffff://'` PORT=${2} PIDFILE="/var/run/`basename ${0}`.${IP}_${PORT}.pid" # kill of the last instance of this monitor if hung and log current pid if [ -f $PIDFILE ] then echo "EAV exceeded runtime needed to kill ${IP}:${PORT}" | logger -p local0.error kill -9 `cat $PIDFILE` > /dev/null 2>&1 fi echo "$$" > $PIDFILE # send request & check for expected response curl -Lsk https://${IP}:${PORT} -c cookiejar.txt | grep "This product is licensed from F5 Networks" > /dev/null # mark node UP if expected response was received if [ $? -eq 0 ] then rm -f $PIDFILE echo "UP" else rm -f $PIDFILE fi # delete APM session curl -Lsk https://${IP}:${PORT}/my.logout.php3 -b cookiejar.txt > /dev/null exit You can save this monitor to your F5 by following SOL13423 and for information on implementing external monitors click here.419Views0likes1Comment
LineRate and Redis pub/sub
Using the pre-installed Redis server on LineRate proxy, we can use pub/sub to push new configuration options and modify the layer 7 data path in real time. Background Each LineRate proxy has multiple data forwarding path processors; each of these processors runs an instance of the Node.js scripting engine. When a new HTTP request has to be processed, one of these script engines will process the request. Which actual script engine handles the request is not deterministic. A traditional approach to updating a script's configuration might be to embed an onRequest function in your script to handle an HTTP POST with new configuration options. However, given that only a single script engine will process this request, only the script running on that engine will 'see' the new options. Scripts running on any other engines will continue to use old options. Here we show you and easy way to push new options to all running processes. How to If you're not already familiar with Node.js and the LineRate scripting engine, you should check out the LineRate Scripting Developer's Guide. Let's jump into the Redis details. Redis is already installed and running on your LineRate proxy, so you can begin to use it immediately. If you're not familiar with the pub/sub concept, it's pretty straight-forward. The idea is that a publisher publishes a message on a particular channel and any subscribers that are subscribed to that same channel will receive the message. In this example, the message will be in JSON format. Be sure to take note of the fact that if your subscriber is not listening on the channel when a message is published, this message will never be seen by that subscriber. I've added some additional code that will store the published options in redis. Any time a subscriber connects, it will check for these values in redis and use them if they exist. This way, any subscriber will always use the most recently published options. Here is the code that will be added to the main script to handle the Redis subscribe function: // load the redis module var redis = require("redis"); // create the subscriber redis client var sub = redis.createClient(); // listen to and process 'message' events sub.on('message', function(channel, message) { // ... // get 'message' and store in 'opts' var opts = JSON.parse(message); // ... }); // subscribe to the 'options' channel sub.subscribe('options'); We can now insert these code pieces into a larger script that uses the options published in the options message. For example, you might want to use LineRate for it's ability to do HTTP traffic replication. You could publish an option called "load" that controls what percentage of requests get replicated. All script engines will 'consume' this message, update the load variable and immediately start replicating only the percentage of requests that you specified. It just so happens we have some code for this. See below in the section sampled_traffic_replication.js for a fully commented script that does sampled traffic replication using parameters received from Redis. It should also be mentioned that if you have multiple LineRate's all performing the same function, they can all subscribe to the same Redis server/channel and all take the appropriate action - all at the same time, all in real-time. Of course we need a way to actually publish new options to the 'options' channel. This could be done in myriad ways. I've included a fully commented Node.js script below called publish_config.js that prompts the user for the appropriate options on the command line and then publishes those options to the 'options' channel. Lastly, here's a sample proxy config snippet for LineRate that you would need: [...] virtual-server vsPrimary attach vipPrimary default attach real-server group ... virtual-server vsReplicate attach vipReplicate default attach real-server group ... virtual-ip vipPrimary admin-status online ip address 192.0.2.10 80 virtual-ip vipReplicate admin-status online ip address 127.0.0.1 8080 [...] sampled_traffic_replication.js "use strict"; var vsm = require('lrs/virtualServerModule'); var http = require('http'); var redis = require("redis"), sub = redis.createClient(); // define initial config options var replicateOptions = { ip: '127.0.0.1', port: 8080, // Replicate every pickInterval requests // by default, don't replicate any traffic pickInterval: 0 }; // pubsub error handling sub.on("error", function(err) { console.log("Redis subscribe Error: " + err); }); // if options already exist in redis, use them sub.on("ready", function() { sub.get('config_options', function (err, reply) { if (reply !== null) { process_options(reply); } }); // switch to subscriber mode to // listen for any published options sub.subscribe('options'); }); function process_options(opts) { opts = JSON.parse(opts); // only update config params if not null if (opts.virtual_server_ip) { replicateOptions.ip = opts.virtual_server_ip; } if (opts.virtual_server_port) { replicateOptions.port = opts.virtual_server_port; } // convert 'load' to 'pickInterval' for internal use if (opts.load) { // convert opts.load string to int opts.load = parseInt(opts.load, 10); if (opts.load === 0) { replicateOptions.pickInterval = opts.load; } else { replicateOptions.pickInterval = Math.round(1 / (opts.load / 100)); } } console.log("Updated options: " + JSON.stringify(replicateOptions)); } var tapServerRequest = function(servReq, servResp, options, onResponse) { // There is no built-in method to clone a request, so we must generate a new // request based on the existing request and send it to the replicate VIP var newReq = http.request({ host: options.ip, port: options.port, method: servReq.method, path: servReq.url}, onResponse); servReq.bindHeaders(newReq); servReq.pipe(newReq); return newReq; } // Listen for config updates on 'options' channel sub.on('message', function(channel, message) { console.log(process.pid + ' Updating config(' + channel + ': ' + message); process_options(message); }); vsm.on('exist', 'vsPrimary', function(vs) { console.log('Replicate traffic script installed on Virtual Server: ' + vs.id); var reqCount = 0; vs.on('request', function(servReq, servResp, cliReq) { var tapStart = Date.now(); var to; var aborted = false; reqCount++; // // decide if request should be replicated; replicate if so // // be sure to handle "0" load scenario gracefully // if (replicateOptions.pickInterval && reqCount % replicateOptions.pickInterval == 0) { var newReq = tapServerRequest(servReq, servResp, replicateOptions, function(resp) { // a close event indicates an improper connection termination resp.on('close', function(err) { console.log('Replicated response error: ' + err); }); resp.on('end', function(err) { console.log('Replicated response error:' + aborted); clearTimeout(to); }); }); // // if replicated request timer exceeds 500ms, abort the request // to = setTimeout(function() { aborted = true; newReq.abort(); }, 500); } // // also send original request along the normal data path // servReq.bindHeaders(cliReq); servReq.pipe(cliReq); cliReq.on('response', function(cliResp) { cliResp.bindHeaders(servResp); cliResp.fastPipe(servResp); }); }); }); publish_config.js "use strict"; var prompt = require('prompt'); var redis = require('redis'); // note you might need Redis server connection // parameters defined here for use in createClient() // method. var redis_client = redis.createClient(); var config_channel = 'options'; var schema = { properties: { virtual_server_ip: { description: 'Virtual Server IP', pattern: /^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$/, message: 'Must be an IP address', required: false }, virtual_server_port: { description: 'Virtual Server port number', pattern: /^[0-9]{1,5}$/, message: 'Must be an integer between 1 and 65535', require: false }, load: { description: 'Percentage of load to replicate', pattern: /^[0-9]{1,3}$/, message: 'Must be an integer between 0 and 100', require: false } } }; prompt.start(); function get_info() { console.log('Enter values; leave blank to not update'); prompt.get(schema, function (err, result) { if (err) { return prompt_error(err); } // // TODO: do some input validation here // var config = JSON.stringify(result) console.log('Sending: ' + config) // publish options via pub/sub redis_publish_message(config_channel, config); redis_client.end(); }); } function redis_publish_message(channel, message) { // publish redis_client.publish(channel,message); // also store JSON message in redis redis_client.set("config_options", message) } function prompt_error(err) { console.log(err); return 1; } //main get_info(); Additional Resources Download LineRate LineRate Scripting Developer's Guide LineRate solution articles LineRate DevCentral265Views0likes0Comments2.5 bad ways to implement a server load balancing architecture
I'm in a bit of mood after reading a Javaworld article on server load balancing that presents some fairly poor ideas on architectural implementations. It's not the concepts that are necessarily wrong; they will work. It's the architectures offered as a method of load balancing made me do a double-take and say "What?" I started reading this article because it was part 2 of a series on load balancing and this installment focused on application layer load balancing. You know, layer 7 load balancing. Something we at F5 just might know a thing or two about. But you never know where and from whom you'll learn something new, so I was eager to dive in and learn something. I learned something alright. I learned a couple of bad ways to implement a server load balancing architecture. TWO LOAD BALANCERS? The first indication I wasn't going to be pleased with these suggestions came with the description of a "popular" load-balancing architecture that included two load balancers: one for the transport layer (layer 4) and another for the application layer (layer 7). In contrast to low-level load balancing solutions, application-level server load balancing operates with application knowledge. One popular load-balancing architecture, shown in Figure 1, includes both an application-level load balancer and a transport-level load balancer. Even the most rudimentary, entry level load balancers on the market today - software and hardware, free and commercial - can handle both transport and application layer load balancing. There is absolutely no need to deploy two separate load balancers to handle two different layers in the stack. This is a poor architecture introducing unnecessary management and architectural complexity as well as additional points of failure into the network architecture. It's bad for performance because it introduces additional hops and points of inspection through which application messages must flow. To give the author credit he does recognize this and offers up a second option to counter the negative impact of the "additional network hops." One way to avoid additional network hops is to make use of the HTTP redirect directive. With the help of the redirect directive, the server reroutes a client to another location. Instead of returning the requested object, the server returns a redirect response such as 303. I found it interesting that the author cited an HTTP response code of 303, which is rarely returned in conjunction with redirects. More often a 302 is used. But it is valid, if not a bit odd. That's not the real problem with this one, anyway. The author claims "The HTTP redirect approach has two weaknesses." That's true, it has two weaknesses - and a few more as well. He correctly identifies that this approach does nothing for availability and exposes the infrastructure, which is a security risk. But he fails to mention that using HTTP redirects introduces additional latency because it requires additional requests that must be made by the client (increasing network traffic), and that it is further incapable of providing any other advanced functionality at the load balancing point because it essentially turns the architecture into a variation of a DSR (direct server return) configuration. THAT"S ONLY 2 BAD WAYS, WHERE'S THE .5? The half bad way comes from the fact that the solutions are presented as a Java based solution. They will work in the sense that they do what the author says they'll do, but they won't scale. Consider this: the reason you're implementing load balancing is to scale, because one server can't handle the load. A solution that involves putting a single server - with the same limitations on connections and session tables - in front of two servers with essentially the twice the capacity of the load balancer gains you nothing. The single server may be able to handle 1.5 times (if you're lucky) what the servers serving applications may be capable of due to the fact that the burden of processing application requests has been offloaded to the application servers, but you're still limited in the number of concurrent users and connections you can handle because it's limited by the platform on which you are deploying the solution. An application server acting as a cluster controller or load balancer simply doesn't scale as well as a purpose-built load balancing solution because it isn't optimized to be a load balancer and its resource management is limited to that of a typical application server. That's true whether you're using a software solution like Apache mod_proxy_balancer or hardware solution. So if you're implementing this type of a solution to scale an application, you aren't going to see the benefits you think you are, and in fact you may see a degradation of performance due to the introduction of additional hops, additional processing, and poorly designed network architectures. I'm all for load balancing, obviously, but I'm also all for doing it the right way. And these solutions are just not the right way to implement a load balancing solution unless you're trying to learn the concepts involved or are in a computer science class in college. If you're going to do something, do it right. And doing it right means taking into consideration the goals of the solution you're trying to implement. The goals of a load balancing solution are to provide availability and scale, neither of which the solutions presented in this article will truly achieve.287Views0likes1CommentDevops Proverb: Process Practice Makes Perfect
#devops Tools for automating – and optimizing – processes are a must-have for enabling continuous delivery of application deployments Some idioms are cross-cultural and cross-temporal. They transcend cultures and time, remaining relevant no matter where or when they are spoken. These idioms are often referred to as proverbs, which carries with it a sense of enduring wisdom. One such idiom, “practice makes perfect”, can be found in just about every culture in some form. In Chinese, for example, the idiom is apparently properly read as “familiarity through doing creates high proficiency”, i.e. practice makes perfect. This is a central tenet of devops, particularly where optimization of operational processes is concerned. The more often you execute a process, the more likely you are to get better at it and discover what activities (steps) within that process may need tweaking or changes or improvements. Ergo, optimization. This tenet grows out of the agile methodology adopted by devops: application release cycles should be nearly continuous, with both developers and operations iterating over the same process – develop, test, deploy – with a high level of frequency. Eventually (one hopes) we achieve process perfection – or at least what we might call process perfection: repeatable, consistent deployment success. It is implied that in order to achieve this many processes will be automated, once we have discovered and defined them in such a way as to enable them to be automated. But how does one automate a process such as an application release cycle? Business Process Management (BPM) works well for automating business workflows; such systems include adapters and plug-ins that allow communication between systems as well as people. But these systems are not designed for operations; there are no web servers or databases or Load balancer adapters for even the most widely adopted BPM systems. One such solution can be found in Electric Cloud with its recently announced ElectricDeploy. Process Automation for Operations ElectricDeploy is built upon a more well known product from Electric Cloud (well, more well-known in developer circles, at least) known as ElectricCommander, a build-test-deploy application deployment system. Its interface presents applications in terms of tiers – but extends beyond the traditional three-tiers associated with development to include infrastructure services such as – you guessed it – load balancers (yes, including BIG-IP) and virtual infrastructure. The view enables operators to create the tiers appropriate to applications and then orchestrate deployment processes through fairly predictable phases – test, QA, pre-production and production. What’s hawesome about the tools is the ability to control the process – to rollback, to restore, and even debug. The debugging capabilities enable operators to stop at specified tasks in order to examine output from systems, check log files, etc..to ensure the process is executing properly. While it’s not able to perform “step into” debugging (stepping into the configuration of the load balancer, for example, and manually executing line by line changes) it can perform what developers know as “step over” debugging, which means you can step through a process at the highest layer and pause at break points, but you can’t yet dive into the actual task. Still, the ability to pause an executing process and examine output, as well as rollback or restore specific process versions (yes, it versions the processes as well, just as you’d expect) would certainly be a boon to operations in the quest to adopt tools and methodologies from development that can aid them in improving time and consistency of deployments. The tool also enables operations to determine what is failure during a deployment. For example, you may want to stop and rollback the deployment when a server fails to launch if your deployment only comprises 2 or 3 servers, but when it comprises 1000s it may be acceptable that a few fail to launch. Success and failure of individual tasks as well as the overall process are defined by the organization and allow for flexibility. This is more than just automation, it’s managed automation; it’s agile in action; it’s focusing on the processes, not the plumbing. MANUAL still RULES Electric Cloud recently (June 2012) conducted a survey on the “state of application deployments today” and found some not unexpected but still frustrating results including that 75% of application deployments are still performed manually or with little to no automation. While automation may not be the goal of devops, but it is a tool enabling operations to achieve its goals and thus it should be more broadly considered as standard operating procedure to automate as much of the deployment process as possible. This is particularly true when operations fully adopts not only the premise of devops but the conclusion resulting from its agile roots. Tighter, faster, more frequent release cycles necessarily puts an additional burden on operations to execute the same processes over and over again. Trying to manually accomplish this may be setting operations up for failure and leave operations focused more on simply going through the motions and getting the application into production successfully than on streamlining and optimizing the processes they are executing. Electric Cloud’s ElectricDeploy is one of the ways in which process optimization can be achieved, and justifies its purchase by operations by promising to enable better control over application deployment processes across development and infrastructure. Devops is a Verb 1024 Words: The Devops Butterfly Effect Devops is Not All About Automation Application Security is a Stack Capacity in the Cloud: Concurrency versus Connections Ecosystems are Always in Flux The Pythagorean Theorem of Operational Risk241Views0likes1CommentLoad Balancing WebSockets
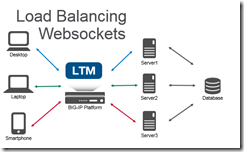
An introduction to WebSockets and how to load balance them. WebSockets creates a responsive experience for end-users by creating a bi-directional communication stream versus the one-way HTTP stream. For example, when you’re waiting at the deli counter you need to take a number. An HTTP method of checking your status in line would be to periodically take your number up to the deli counter to see if you’re next in line. The WebSocket method for notification would be to have someone shout out the number to you when you’re next. One of these methods is more convenient! HTTP is a stateless protocol. It looks like a series of request/responses that originate from the client to the server. WebSockets is a bi-directional protocol that allows the client to send requests to the server AND allows the server to push responses to the client. On the BIG-IP with LTM the default HTTP profile has supported the WebSocket upgrade header since 11.4.0. It is possible to use a FastL4 profile to treat all the traffic as TCP, but you lose some resources like the ability to set X-Forwarded-For headers to provide visibility to the client IP when using SNAT, cookie persistence (avoid issues when client IP changes), and the ability to route traffic based on the HTTP request. Given the long duration of a WebSocket connection; you can also utilize pool member connection limits and least connection load balancing to ensure an even distribution of traffic across multiple nodes. General tips for the backend servers is to ensure that the servers are stateless (any server can generate a response for any client) or share state. SignalR (ASP.NET) has a nice introduction to scaling out (don’t forget to use the same MachineKey across IIS servers). Socket.IO (Node.JS) has helpful documentation that covers utilizing multiple nodes (Redis works well as a provided adapter). Not all clients will support WebSocket natively, and/or web proxy/firewalls may not allow these connections. Fallback mechanisms exist for both SignalR/Socket.IO to allow communication without support for WebSockets (via HTTP). Using these tips to load balance WebSockets you can create a highly available service of WebSocket servers or create a demo that combines an Apache web, Node.JS Socket.IO, and SignalR ASP.NET server under a single URL!8.9KViews0likes10CommentsInside Look - PCoIP Proxy for VMware Horizon View
I sit down with F5 Solution Architect Paul Pindell to get an inside look at BIG-IP's native support for VMware's PCoIP protocol. He reviews the architecture, business value and gives a great demo on how to configure BIG-IP. BIG-IP APM offers full proxy support for PC-over-IP (PCoIP), a leading virtual desktop infrastructure (VDI) protocol. F5 is the first to provide this functionality which allows organizations to simplify their VMware Horizon View architectures. Combining PCoIP proxy with the power of the BIG-IP platform delivers hardened security and increased scalability for end-user computing. In addition to PCoIP, F5 supports a number of other VDI solutions, giving customers flexibility in designing and deploying their network infrastructure. ps Related: F5 Friday: Simple, Scalable and Secure PCoIP for VMware Horizon View Solutions for VMware applications F5's YouTube Channel In 5 Minutes or Less Series (24 videos – over 2 hours of In 5 Fun) Inside Look Series Life@F5 Series Technorati Tags: vdi,PCoIP,VMware,Access,Applications,Infrastructure,Performance,Security,Virtualization,silva,video,inside look,big-ip,apm Connect with Peter: Connect with F5:331Views0likes0CommentsDNSSEC: Is Your Infrastructure Ready?
A few months ago, we teamed with Infoblox for a DNSSEC webinar. Jonathan George, F5 Product Marketing Manager, leads with myself and Cricket Liu of Infoblox as background noise. He’s a blast as always and certainly knows his DNS. So, learn how F5 enables you to deploy DNSSEC quickly and easily into an existing GSLB environment with BIG-IP Global Traffic Manager (GTM). BIG-IP GTM streamlines encryption key generation and distribution by dynamically signing DNS responses in real-time. Running time: 49:20 </p> <p>ps</p> <p>Resources:</p> <ul> <li><a href="http://www.f5.com/news-press-events/web-media/" _fcksavedurl="http://www.f5.com/news-press-events/web-media/">F5 Web Media</a></li> <li><a href="http://www.youtube.com/user/f5networksinc" _fcksavedurl="http://www.youtube.com/user/f5networksinc">F5 YouTube Channel</a></li> <li><a href="http://www.f5.com/products/big-ip/global-traffic-manager.html" _fcksavedurl="http://www.f5.com/products/big-ip/global-traffic-manager.html">BIG-IP GTM</a></li> <li><a href="http://www.f5.com/pdf/white-papers/dnssec-wp.pdf" _fcksavedurl="http://www.f5.com/pdf/white-papers/dnssec-wp.pdf">DNSSEC: The Antidote to DNS Cache Poisoning and Other DNS Attacks (whitepaper)</a> | <a href="http://devcentral.f5.com/s/weblogs/interviews/archive/2009/12/04/audio-tech-brief-dnssec-the-antidote-to-dns.aspx" _fcksavedurl="http://devcentral.f5.com/s/weblogs/interviews/archive/2009/12/04/audio-tech-brief-dnssec-the-antidote-to-dns.aspx">Audio</a></li> <li><a href="http://www.cricketondns.com" _fcksavedurl="http://www.cricketondns.com">Cricket on DNS</a></li> <li><a href="http://www.youtube.com/user/InfobloxInc" _fcksavedurl="http://www.youtube.com/user/InfobloxInc">Infoblox YouTube Channel</a></li> </ul> <p>Technorati Tags: <a href="http://devcentral.f5.com/s/weblogs/psilva/psilva/psilva/archive/2011/05/09/" _fcksavedurl="http://devcentral.f5.com/s/weblogs/psilva/psilva/psilva/archive/2011/05/09/">F5</a>, <a href="http://technorati.com/tags/webinar" _fcksavedurl="http://technorati.com/tags/webinar">webinar</a>, <a href="http://technorati.com/tags/Pete+Silva" _fcksavedurl="http://technorati.com/tags/Pete+Silva">Pete Silva</a>, <a href="http://technorati.com/tags/security" _fcksavedurl="http://technorati.com/tags/security">security</a>, <a href="http://technorati.com/tag/business" _fcksavedurl="http://technorati.com/tag/business">business</a>, <a href="http://technorati.com/tag/education" _fcksavedurl="http://technorati.com/tag/education">education</a>, <a href="http://technorati.com/tag/technology" _fcksavedurl="http://technorati.com/tag/technology">technology</a>, <a href="http://technorati.com/tags/internet" _fcksavedurl="http://technorati.com/tags/internet">internet, </a><a href="http://technorati.com/tags/big-ip" _fcksavedurl="http://technorati.com/tags/big-ip">big-ip</a>, <a href="http://technorati.com/tag/dnssec" _fcksavedurl="http://technorati.com/tag/dnssec">dnssec</a>, <a href="http://technorati.com/tags/infoblox" _fcksavedurl="http://technorati.com/tags/infoblox">infoblox</a> <a href="http://technorati.com/tags/dns" _fcksavedurl="http://technorati.com/tags/dns">dns</a></p> <table border="0" cellspacing="0" cellpadding="2" width="378"><tbody> <tr> <td valign="top" width="200">Connect with Peter: </td> <td valign="top" width="176">Connect with F5: </td> </tr> <tr> <td valign="top" width="200"><a href="http://www.linkedin.com/pub/peter-silva/0/412/77a" _fcksavedurl="http://www.linkedin.com/pub/peter-silva/0/412/77a"><img style="border-bottom: 0px; border-left: 0px; display: inline; border-top: 0px; border-right: 0px" title="o_linkedin[1]" border="0" alt="o_linkedin[1]" src="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_linkedin.png" _fcksavedurl="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_linkedin.png" width="24" height="24" /></a> <a href="http://devcentral.f5.com/s/weblogs/psilva/Rss.aspx" _fcksavedurl="http://devcentral.f5.com/s/weblogs/psilva/Rss.aspx"><img style="border-bottom: 0px; border-left: 0px; display: inline; border-top: 0px; border-right: 0px" title="o_rss[1]" border="0" alt="o_rss[1]" src="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_rss.png" _fcksavedurl="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_rss.png" width="24" height="24" /></a> <a href="http://www.facebook.com/f5networksinc" _fcksavedurl="http://www.facebook.com/f5networksinc"><img style="border-bottom: 0px; border-left: 0px; display: inline; border-top: 0px; border-right: 0px" title="o_facebook[1]" border="0" alt="o_facebook[1]" src="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_facebook.png" _fcksavedurl="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_facebook.png" width="24" height="24" /></a> <a href="http://twitter.com/psilvas" _fcksavedurl="http://twitter.com/psilvas"><img style="border-bottom: 0px; border-left: 0px; display: inline; border-top: 0px; border-right: 0px" title="o_twitter[1]" border="0" alt="o_twitter[1]" src="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_twitter.png" _fcksavedurl="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_twitter.png" width="24" height="24" /></a> </td> <td valign="top" width="176"> <a href="http://bitly.com/nIsT1z?r=bb" _fcksavedurl="http://bitly.com/nIsT1z?r=bb"><img style="border-right-width: 0px; display: inline; border-top-width: 0px; border-bottom-width: 0px; border-left-width: 0px" title="o_facebook[1]" border="0" alt="o_facebook[1]" src="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_facebook.png" _fcksavedurl="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_facebook.png" width="24" height="24" /></a> <a href="http://bitly.com/rrAfiR?r=bb" _fcksavedurl="http://bitly.com/rrAfiR?r=bb"><img style="border-right-width: 0px; display: inline; border-top-width: 0px; border-bottom-width: 0px; border-left-width: 0px" title="o_twitter[1]" border="0" alt="o_twitter[1]" src="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_twitter.png" _fcksavedurl="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_twitter.png" width="24" height="24" /></a> <a href="http://bitly.com/neO7Pm?r=bb" _fcksavedurl="http://bitly.com/neO7Pm?r=bb"><img style="border-right-width: 0px; display: inline; border-top-width: 0px; border-bottom-width: 0px; border-left-width: 0px" title="o_slideshare[1]" border="0" alt="o_slideshare[1]" src="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_slideshare.png" _fcksavedurl="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_slideshare.png" width="24" height="24" /></a> <a href="http://bitly.com/mOVxf3?r=bb" _fcksavedurl="http://bitly.com/mOVxf3?r=bb"><img style="border-right-width: 0px; display: inline; border-top-width: 0px; border-bottom-width: 0px; border-left-width: 0px" title="o_youtube[1]" border="0" alt="o_youtube[1]" src="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_youtube.png" _fcksavedurl="http://devcentral.f5.com/s/weblogs/images/devcentral_f5_com/weblogs/macvittie/1086440/o_youtube.png" width="24" height="24" /></a></td> </tr> </tbody></table></body></html> ps Resources: F5 Web Media F5 YouTube Channel BIG-IP GTM DNSSEC: The Antidote to DNS Cache Poisoning and Other DNS Attacks (whitepaper) | Audio Cricket on DNS Infoblox YouTube Channel301Views0likes1Comment