BIG-IP Configuration Conversion Scripts
Kirk Bauer, John Alam, and Pete White created a handful of perl and/or python scripts aimed at easing your migration from some of the “other guys” to BIG-IP.While they aren’t going to map every nook and cranny of the configurations to a BIG-IP feature, they will get you well along the way, taking out as much of the human error element as possible.Links to the codeshare articles below. Cisco ACE (perl) Cisco ACE via tmsh (perl) Cisco ACE (python) Cisco CSS (perl) Cisco CSS via tmsh (perl) Cisco CSM (perl) Citrix Netscaler (perl) Radware via tmsh (perl) Radware (python)1.6KViews1like13Comments
BIG-IP LTM VE: Transfer your iRules in style with the iRule Editor
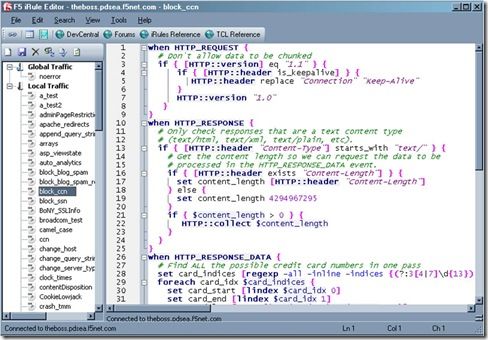
The new LTM VE has opened up the possibilities for writing, testing and deploying iRules in a big way. It’s easier than ever to get a test environment set up in which you can break things develop to your heart’s content. This is fantastic news for us iRulers that want to be doing the newest, coolest stuff without having to worry about breaking a production system. That’s all well and good, but what the heck do you do to get all of your current stuff onto your test system? There are several options, ranging from copy and paste (shudder) to actual config copies and the like, which all work fine. Assuming all you’re looking for though is to transfer over your iRules, like me, the easiest way I’ve found is to use the iRule editor’s export and import features. It makes it literally a few clicks and super easy to get back up and running in the new environment. First, log into your existing LTM system with your iRule editor (you are using the editor, right? Of course you are…just making sure). You’ll see a screen something like this (right) with a list of a bagillionty iRules on the left and their cool, color coded awesomeness on the right. You can go through and select iRules and start moving them manually, but there’s really no need. All you need to do is go up to the File –> Archive –> Export option and let it do its magic. All it’s doing is saving text files to your local system to archive off all of your iRuley goodness. Once that’s done, you can then spin up your new LTM VE and get logged in via the iRule editor over there. Connect via the iRule editor, and go to File –> Archive –> Import, shown below. Once you choose the import option you’ll start seeing your iRules popping up in the left-hand column, just like you’re used to. This will take a minute depending on how many iRules you have archived (okay, so I may have more than a few iRules in my collection…) but it’s generally pretty snappy. One important thing to note at his point, however, is that all of your iRules are bolded with an asterisk next to them. This means they are not saved in their current state on the LTM. If you exit at this point, you’ll still be iRuleless, and no one wants that. Luckily Joe thought of that when building the iRule editor, so all you need to do is select File –> Save All, and you’ll be most of the way home. I say most of the way because there will undoubtedly be some errors that you’ll need to clean up. These will be config based errors, like pools that used to exist on your old system and don’t now, etc. You can either go create the pools in the config or comment out those lines. I tend to try and keep my iRules as config agnostic as possible while testing things, so there aren’t a ton of these but some of them always crop up. The editor makes these easy to spot and fix though. The name of the iRule that’s having a problem will stay bolded and any errors in that particular code will be called out (assuming you have that feature turned on) so you can pretty quickly spot them and fix them. This entire process took me about 15 minutes, including cleaning up the code in certain iRules to at least save properly on the new system, and I have a bunch of iRules, so that’s a pretty generous estimate. It really is quick, easy and painless to get your code onto an LTM VE and get hacking coding. An added side benefit, but a cool one, is that you now have your iRules backed up locally. Not only does this mean you’re double plus sure that they won’t be lost, but it means the next time you want to deploy them somewhere, all you have to do is import from the editor. So if you haven’t yet, go download your BIG-IP LTM VE and get started. I can’t recommend it enough. Also make sure to check out some of the really handy DC content that shows you how to tweak it for more interfaces or Joe’s supremely helpful guide on how to use a single VM to run an entire client/LTM/server setup. Wicked cool stuff. Happy iRuling. #Colin1.3KViews0likes1CommentIP::addr and IPv6
Did you know that all address internal to tmm are kept in IPv6 format? If you’ve written external monitors, I’m guessing you knew this. In the external monitors, for IPv4 networks the IPv6 “header” is removed with the line: IP=`echo $1 | sed 's/::ffff://'` IPv4 address are stored in what’s called “IPv4-mapped” format. An IPv4-mapped address has its first 80 bits set to zero and the next 16 set to one, followed by the 32 bits of the IPv4 address. The prefix looks like this: 0000:0000:0000:0000:0000:ffff: (abbreviated as ::ffff:, which looks strickingly simliar—ok, identical—to the pattern stripped above) Notation of the IPv4 section of the IPv4-formatted address vary in implementations between ::ffff:192.168.1.1 and ::ffff:c0a8:c8c8, but only the latter notation (in hex) is supported. If you need the decimal version, you can extract it like so: % puts $x ::ffff:c0a8:c8c8 % if { [string range $x 0 6] == "::ffff:" } { scan [string range $x 7 end] "%2x%2x:%2x%2x" ip1 ip2 ip3 ip4 set ipv4addr "$ip1.$ip2.$ip3.$ip4" } 192.168.200.200 Address Comparisons The text format is not what controls whether the IP::addr command (nor the class command) does an IPv4 or IPv6 comparison. Whether or not the IP address is IPv4-mapped is what controls the comparison. The text format merely controls how the text is then translated into the internal IPv6 format (ie: whether it becomes a IPv4-mapped address or not). Normally, this is not an issue, however, if you are trying to compare an IPv6 address against an IPv4 address, then you really need to understand this mapping business. Also, it is not recommended to use 0.0.0.0/0.0.0.0 for testing whether something is IPv4 versus IPv6 as that is not really valid a IP address—using the 0.0.0.0 mask (technically the same as /0) is a loophole and ultimately, what you are doing is loading the equivalent form of a IPv4-mapped mask. Rather, you should just use the following to test whether it is an IPv4-mapped address: if { [IP::addr $IP1 equals ::ffff:0000:0000/96] } { log local0. “Yep, that’s an IPv4 address” } These notes are covered in the IP::addr wiki entry. Any updates to the command and/or supporting notes will exist there, so keep the links handy. Related Articles F5 Friday: 'IPv4 and IPv6 Can Coexist' or 'How to eat your cake ... Service Provider Series: Managing the ipv6 Migration IPv6 and the End of the World No More IPv4. You do have your IPv6 plan running now, right ... Question about IPv6 - BIGIP - DevCentral - F5 DevCentral ... Insert IPv6 address into header - DevCentral - F5 DevCentral ... Business Case for IPv6 - DevCentral - F5 DevCentral > Community ... We're sorry. The IPv4 address you are trying to reach has been ... Don MacVittie - F5 BIG-IP IPv6 Gateway Module1.1KViews1like1CommentBIG-IP Configuration Object Naming Conventions
George posted an excellent blog on hostname nomenclature a while back, but something we haven’t discussed much in this space is a naming convention for the BIG-IP configuration objects. Last week, DevCentral community user Deon posted a question on exactly that. Sometimes there are standards just for the sake of having one, but in most cases, and particularly in this case, having standards is a very good thing. Señor Forum, hoolio, and MVP hamish weighed in with some good advice. [app name]_[protocol]_[object type] Examples: www.example.com_http_vs www.example.com_http_pool www.example.com_http_monitor As hoolio pointed out in the forum, each object now has a description field, so the metadata capability is there to establish identifying information (knowledge base IDs, troubleshooting info, application owners), but having an object name that is quickly searchable and identifiable to operational staff is key. Hamish had a slight alternative format for virtuals: [fqdn]_[port] For network virtuals, I’ve always made the network part of the name, as hamish also recommends in his guidance: network VS's tend to be named net-net.num.dot.ed-masklen. e.g. net-0.0.0.0-0 is the default address. Where they conflict (e.g. two defaults depending on src clan, it gets an extra descriptor between net- and the ip address. e.g. net-wireless-0.0.0.0-0 (Default network VS for a wireless VLAN). I don't currently have any network VS's for specific ports. But they'd be something like net-0.0.0.0-0-port Your Turn What standards do you use? Share in the comments section below, or post to the forum thread.923Views0likes0CommentsStop that F5 Key From Refreshing the Page
No, not “us” F5, the F5 key on the keyboard. You know, the one you hit relentlessly to refresh the page (well, the one I hit relentlessly during NFL games to update my fantasy football stats). Anyway, I was perusing the forums today, trying to catch up from a week attending our very excellent annual sales conference, and I noticed a thread that had to be shared. The Question Is there a way of preventing users from using the F5 button to refresh a web page? – DevCentral user ringoseagull (nice handle, btw!) The Solution F5er and very active forum patrolman nitass posted back within 30 minutes with a solution, featuring iRules of course! We’ve seen javascript insert iRules before, but this is a pretty handy use case, so I thought I’d share. when HTTP_REQUEST { STREAM::disable if {[HTTP::version] eq "1.1"} { if { [HTTP::header is_keepalive] } { HTTP::header replace "Connection" "Keep-Alive" } HTTP::version 1.0 } } when HTTP_RESPONSE { if {[HTTP::header Content-Type] starts_with "text/"} { STREAM::expression "@@@" STREAM::enable } } when STREAM_MATCHED { STREAM::disable } This iRule uses the stream profile to find the head tag and insert the javascript necessary to control the F5 keycode behavior. Curl testing shows the javascript successfully delivered: [root@ve1023:Active] config # curl -i http://172.28.65.152 HTTP/1.1 200 OK Dat e: Fri, 11 Nov 2011 15:24:33 GMT Server: Apache/2.2.3 (CentOS) Last-Modified: Fri, 11 Nov 2011 14:48:14 GMT ETag: "4183e4-3e-9c564780" Accept-Ranges: bytes Connection: close Content-Type: text/html; charset=UTF-8 This is 101 host. Nice work, nitass! Related Articles iRules Wiki Home - DevCentral Wiki iRules Reference - DevCentral Wiki STREAM::expression - DevCentral Wiki DevCentral Groups - iRules iRules 101 - #01 - Introduction to iRules > DevCentral > Tech Tips ...849Views0likes0CommentsBIG-IP VE on Google Cloud Platform
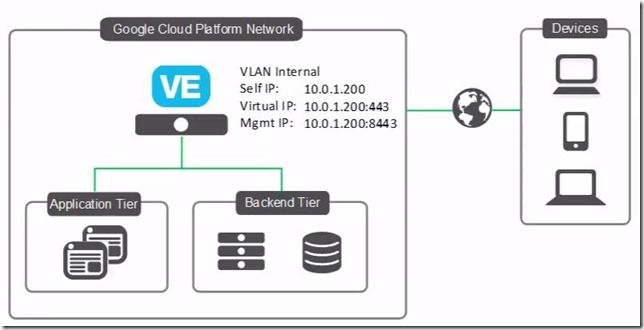
Hot off Cloud Month, let’s look at how to deploy BIG-IP Virtual Edition on the Google Cloud Platform. This is a simple single-NIC, single IP deployment, which means that both management traffic and data traffic are going through the same NIC and are accessible with the same IP address. Before you can create this deployment, you need a license from F5. You can also get a trial license here. Also, we're using BIG-IP VE version 13.0.0 HF2 EHF3 for this example. Alright, let’s get started. Open the console, go to Cloud Launcher and search for F5. Pick the version you want. Now click Launch on Compute Engine. I’m going to change the name so the VM is easier to find… For everything else, I’ll leave the defaults. And then down under firewall, if these ports aren’t already open on your network, you can open 22, which you need so you can use SSH to connect to the instance, and 8443, so you can use the BIG-IP Configuration utility—the web tool that you use to manage the BIG-IP. Now click Deploy. It takes just a few minutes to deploy. And Deployed. When you’re done, you can connect straight from the Google console. This screen cap shows SSH but if you use the browser window, you need to change the Linux username to admin in order to connect. Once done, you'll get that command line. If you choose the gcloud command line option and then run in the gcloud shell, you need to put admin@ in front of the instance name in order to connect. We like using putty so first we need to go get the external IP address of the instance. So I look at the instance and copy the external IP. Then we go into Metadata > SSH keys to confirm that the keys are there. (Added earlier), Whichever keys you want to use to connect, you should put them here. BIG-IP VE grabs these keys every minute or so, so any of the non-expired keys in this list can access the instance. If you remove keys from this list, they’ll be removed from BIG-IP and will no longer have access. You do have the option to edit the VM instance and block project-wide keys if you’d like. Because my keys are already in this list I can open Putty now, and then specify my keys in order to connect. The reason that we're using ssh to connect is that you need to set an admin password that’s used to connect to the BIG-IP Config utility. So I’m going to set the admin password here… (and again, you can do these same steps, no matter how you connect to the instance) tmsh Command is: modify auth modify auth password admin And then: save sys config to save the change. Now we can connect and log in to the BIG-IP Config utility by using https, the external IP and port 8443. Now type admin and the password we just set. Then we can proceed with licensing and provisioning BIG-IP VE. A few other notes: If you’re used to creating a self IP and VLAN, you don’t need to do that. In this single NIC deployment, those things are taken care of for you. If you want to start sending traffic, just set up your pool and virtual server the way you normally would. Just make sure if your app is using port 443, for example, that you add that firewall rule to your network or your instance. And finally, you most likely want to make your external IP address one that is static, and you can do that in the UI by choosing Networking, then External IP addresses, then Type). If you need any help, here's the Google Cloud Platform/BIG-IP VE Setup Guide and/or watch the full video. ps837Views0likes1CommentNetworking Options with LTM VE
If you haven’t yet downloaded the BIG-IP LTM VE trial, I highly suggest you do. It is a fully-functional LTM, rate-limited to 1Mbps throughput. If you’re not familiar with virtualized environments, hopefully this blog will fill in some blanks for how to get started on the network front. Getting Started Before downloading your VE image, you need to choose what virtualization environment you’re installing into. The supported options in the type 1 hypervisor are VMWare ESX version 4 and ESXi version 4. For the type 2 hypervisor (requiring a host OS such as linux or Microsoft Windows) the supported option is VMWare Workstation 7, which offers a 30-day free trial that I recommend you give a shot, or for those with experience on VMWare player, that also will suffice if you are at version 3. Note, however, that VMWare player is not supported by F5. Hypervisor Type 2 Options – VMWare Workstation & Player In LTM VE, you have three interfaces—one managment and two data (1.1 & 1.2). On the Workstation/Player products, you specify in the virtual appliance settings how the interfaces will connect. You can specify any of the following interface types: Bridged – Allows access through your physical NIC to participate in the local area network. NAT – Allows access through your physical NIC, but utilizes your machines IP and translates for VM traffic. Host Only – Networks are defined locally in virtual nics that have no significance outside your locally defined virtualization environment. With the Workstation product, there is a Virtual Network Editor application where you can define the networks your virtual appliances will use, as well as setting dhcp options, etc. The player doesn’t have this application, and doesn’t give the custom option in the GUI interface, but the settings can be configured manually in the appliance configuration files (shown below). To get started quickly, I bridge the management interface so I can download directly from the management shell. I use a host-only interface assigned at layer3 on both my laptop and the VE image so I can run test traffic against my iRules for syntax and functional checking. I have a virtual appliance on a layer2 network (layer3 for VE and the server appliance, but there isn’t a layer3 interface for vmware itself) between it and VE so I can pass traffic from my laptop through VE to the vm server and back as necessary for testing. A diagram detailing this is shown below to the left of the matching configuration options set in the virtual appliance files. # MGMT NETWORK ethernet0.present = "true" ethernet0.virtualDev = "vlance" ethernet0.addressType = "generated" ethernet0.connectionType = "bridged" ethernet0.startConnected = "true" # INT 1.1 ethernet1.present = "true" ethernet1.virtualDev = "e1000" ethernet1.addressType = "generated" ethernet1.connectionType = "custom" ethernet1.startConnected = "true" ethernet1.vnet = "VMnet1" # INT 1.2 ethernet2.present = "true" ethernet2.virtualDev = "e1000" ethernet2.addressType = "generated" ethernet2.connectionType = "custom" ethernet2.startConnected = "true" ethernet2.vnet = "VMnet2" I think in order to take advantage of route domains on the workstation product, you’d need a couple virtual appliances in different vmnets that are only layer2 aware. Still, there are plenty of possibilities with apache vserver configurations if you have the memory to spin up a virtual appliance in addition to the BIG-IP LTM VE. Hypervisor Type 1 Options – VMWare ESX 4/ ESXi 4 In ESX/ESXi, it’s both more complicated and more simple. Yeah, I said that. The assigning of interfaces is trivial, as there really isn’t a concept at the virtual appliance level of bridging, natting, or host only. The ESXi platform has an underlying virtual switching infrastructure where all the science of networking is configured. You can teem your nics and run all your vlans across them, or you can segment by function. When deploying the .ova image to ESXi, the only interesting questions are what datastore you will use to house your VE image and what networks to apply to the VE interfaces. Given that you cannot create them on the fly, you’ll need to do some prep work to make sure your interfaces are already defined before deploying the image. Questions? We turned on an LTM VE specific forum today should you have any questions regarding installation, network configuration, VE options, etc. We hope you get as much use and enjoyment out of this release as we do.717Views0likes3Comments
Hourly Licensing Model – F5 delivers in AWS Marketplace
#cloud #SDAS #AWS And you can try it out for free... June 30, 2014 (The Internet) Today F5 Networks, which delivers solutions for an application world, announced it had completed jumping through the hoops necessary to offer an hourly (utility) billing model for its BIG-IP VE (Virtual Edition) in the Amazon Web Services (AWS) cloud. Not only has F5 announced availability of the industry's leading application delivery services for deployment in AWS with a utility billing model, but the offering includes a variety of options which organizations can take advantage of: Three sizes of BIG-IP VE including 25 Mbps, 200 Mbps and 1Gbps. Two BYOL (Bring Your Own License) options as well as a modular option A free 30 day trial offering with Best licensing and 200 Mbps of throughput BIG-IP VE for AWS includes not only the industry's most trusted load balancing service but also the following capabilities and Software Defined Application Services (SDAS) designed to protect and enhance application security and performance: An integrated WAF (Web Application Firewall) DDoS Protection Caching, compression and acceleration Advanced Load Balancing Algorithms including least connections and weighted round robin. Additionally, BIG-IP VE for AWS supports the use of iApps for rapid provisioning in the cloud or on-premise. iApps are application-driven service templates that encapsulate best practice configurations as determined by lengthy partnerships with leading application providers as well as hundreds of thousands of real deployments across a broad set of verticals including 94% of the Fortune 50. The availability of BIG-IP VE for AWS further supports F5 Synthesis' vision to leave no application behind, regardless of location or service requirements. Through Synthesis' Intelligent Service Orchestration, organizations can enjoy seamless licensing, deployment and management of F5 services across on-premise and cloud-based environments. The availability of BIG-IP VE for AWS extends F5 service fabric into the most popular cloud environment today, and gives organizations the ability to migrate applications to the cloud without compromising on security or performance requirements. To celebrate this most momentous occasion you can try out BIG-IP in the AWS marketplace for free (for 30 days) or receive $100 credit from AWS by activating participating products between July 1 and July 31, 2014: These offers apply to the F5 BIG-IP Virtual Edition for AWS 200Mbps Hourly (Best) through AWS Marketplace: 30 Day Free Trial Available The BIG-IP Virtual Edition is an application delivery services platform for the Amazon Web Services cloud. From traffic management and service offloading to acceleration and security, the BIG-IP Virtual Edition delivers agility - and ensures your applications are fast, secure, and available. Options include: - BIG-IP Local Traffic Manager, Global Traffic Manager, Application Acceleration Manager, Advanced Firewall Manager, Access Policy Manager, Application Security Manager, SDN Services and Advanced Routing, including support for AWS CloudHSM for cryptographic operations and key storage. AWS – Offer (Credit) Customers who activate a free trial for any participating product (that includes F5 BIG-IP) between July 1 and July 31, 2014 and use the product for a minimum of 120 hours before August 31, 2014 , will receive a $100 AWS Promotional Credit. Limit two, $100 AWS Promotional Credits per customer; one per participating software seller. . For more information: F5 Synthesis F5 Solutions Available in the AWS Marketplace F5 BIP-IP Virtual Editions477Views0likes2Comments
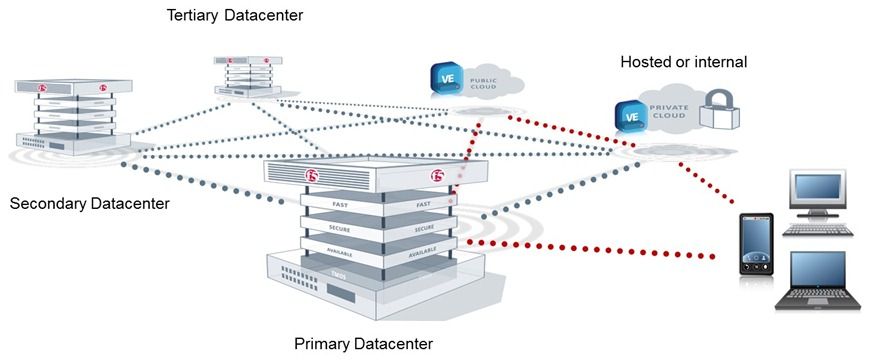
Databases in the Cloud Revisited
A few of us were talking on Facebook about high speed rail (HSR) and where/when it makes sense the other day, and I finally said that it almost never does. Trains lost out to automobiles precisely because they are rigid and inflexible, while population densities and travel requirements are highly flexible. That hasn’t changed since the early 1900s, and isn’t likely to in the future, so we should be looking at different technologies to answer the problems that HSR tries to address. And since everything in my universe is inspiration for either blogging or gaming, this lead me to reconsider the state of cloud and the state of cloud databases in light of synergistic technologies (did I just use “synergistic technologies in a blog? Arrrggghhh…). There are several reasons why your organization might be looking to move out of a physical datacenter, or to have a backup datacenter that is completely virtual. Think of the disaster in Japan or hurricane Katrina. In both cases, having even the mission critical portions of your datacenter replicated to the cloud would keep your organization online while you recovered from all of the other very real issues such a disaster creates. In other cases, if you are a global organization, the cost of maintaining your own global infrastructure might well be more than utilizing a global cloud provider for many services… Though I’ve not checked, if I were CIO of a global organization today, I would be looking into it pretty closely, particularly since this option should continue to get more appealing as technology continues to catch up with hype. Today though, I’m going to revisit databases, because like trains, they are in one place, and are rigid. If you’ve ever played with database Continuous Data Protection or near-real-time replication, you know this particular technology area has issues that are only now starting to see technological resolution. Over the last year, I have talked about cloud and remote databases a few times, talking about early options for cloud databases, and mentioning Oracle Goldengate – or praising Goldengate is probably more accurate. Going to the west in the US? HSR is not an option. The thing is that the options get a lot more interesting if you have Goldengate available. There are a ton of tools, both integral to database systems and third-party that allow you to encrypt data at rest these days, and while it is not the most efficient access method, it does make your data more protected. Add to this capability the functionality of Oracle Goldengate – or if you don’t need heterogeneous support, any of the various database replication technologies available from Oracle, Microsoft, and IBM, you can seamlessly move data to the cloud behind the scenes, without interfering with your existing database. Yes, initial configuration of database replication will generally require work on the database server, but once configured, most of them run without interfering with the functionality of the primary database in any way – though if it is one that runs inside the RDBMS, remember that it will use up CPU cycles at the least, and most will work inside of a transaction so that they can insure transaction integrity on the target database, so know your solution. Running inside the primary transaction is not necessary, and for many uses may not even be desirable, so if you want your commits to happen rapidly, something like Goldengate that spawns a separate transaction for the replica are a good option… Just remember that you then need to pay attention to alerts from the replication tool so that you don’t end up with successful transactions on the primary not getting replicated because something goes wrong with the transaction on the secondary. But for DBAs, this is just an extension of their daily work, as long as someone is watching the logs. With the advent of Goldengate, advanced database encryption technology, and products like our own BIG-IPWOM, you now have the ability to drive a replica of your database into the cloud. This is certainly a boon for backup purposes, but it also adds an interesting perspective to application mobility. You can turn on replication from your data center to the cloud or from cloud provider A to cloud provider B, then use VMotion to move your application VMS… And you’re off to a new location. If you think you’ll be moving frequently, this can all be configured ahead of time, so you can flick a switch and move applications at will. You will, of course, have to weigh the impact of complete or near-complete database encryption against the benefits of cloud usage. Even if you use the adaptability of the cloud to speed encryption and decryption operations by distributing them over several instances, you’ll still have to pay for that CPU time, so there is a balancing act that needs some exploration before you’ll be certain this solution is a fit for you. And at this juncture, I don’t believe putting unencrypted corporate data of any kind into the cloud is a good idea. Every time I say that, it angers some cloud providers, but frankly, cloud being new and by definition shared resources, it is up to the provider to prove it is safe, not up to us to take their word for it. Until then, encryption is your friend, both going to/from the cloud and at rest in the cloud. I say the same thing about Cloud Storage Gateways, it is just a function of the current state of cloud technology, not some kind of unreasoning bias. So the key then is to make sure your applications are ready to be moved. This is actually pretty easy in the world of portable VMs, since the entire VM will pick up and move. The only catch is that you need to make sure users can get to the application at the new location. There are a ton of Global DNS solutions like F5’s BIG-IP Global Traffic Manager that can get your users where they need to be, since your public-facing IPs will be changing when moving from organization to organization. Everything else should be set, since you can use internal IP addresses to communicate between your application VMs and database VMs. Utilizing a some form of in-flight encryption and some form of acceleration for your database replication will round out the solution architecture, and leave you with a road map that looks more like a highway map than an HSR map. More flexible, more pervasive.365Views0likes0CommentsDNS Architecture in the 21st Century
It is amazing if you stop and think about it, how much we utilize DNS services, and how little we think about them. Every organization out there is running DNS, and yet there is not a ton of traction in making certain your DNS implementation is the best it can be. Oh sure, we set up a redundant pair of DNS servers, and some of us (though certainly not all of us) have patched BIND to avoid major vulnerabilities. But have you really looked at how DNS is configured and what you’ll need to keep your DNS moving along? If you’re looking close at IPv6 or DNSSEC, chances are that you have. If you’re not looking into either of these, you probably aren’t even aware that ISC – the non-profit responsible for BIND – is working on a new version. Or that great companies like Infoblox (fair disclosure, they’re an F5 partner) are out there trying to make DNS more manageable. With the move toward cloud computing and the need to keep multiple cloud providers available (generally so your app doesn’t go offline when a cloud provider does, but at a minimum for a negotiation tool), and the increasingly virtualized nature of our application deployments, DNS is taking on a new importance. In particular, distributed DNS is taking on a new importance. What a company with three datacenters and two cloud providers must do today, only ISPs and a few very large organizations did ten years ago. And that complexity shows no signs of slacking. While the technology that is required to operate in a multiple datacenter (whether those datacenters are in the cloud or on your premise) environment is available today, as I alluded to above, most of us haven’t been paying attention. No surprise with the number of other issues on our plates, eh? So here’s a quick little primer to give you some ideas to start with when you realize you need to change your DNS architecture. It is not all-inclusive, the point is to give you ideas you can pursue to get started, not teach you all that some of the experts I spent part of last week with could offer. In a massively distributed environment, DNS will have to direct users to the correct location – which may not be static (Lori tells me the term for this is “hyper-hybrid”) In a IPv6/IPv4 world, DNS will have to serve up both types of addresses, depending upon the requestor Increasingly, DNSSEC will be a requirement to play in the global naming game. While most orgs will go there with dragging feet, they will still go The failure of a cloud, or removal of a cloud from the list of options for an app (as elasticity contracts) will require dynamic changes in DNS. Addition will follow the same rules Multiple DNS servers in multiple locations will have to remain synched to cover a single domain. So the question is where do you begin if you’re like so many people and vaguely looked into DNSSEC or DNS for IPv6, but haven’t really stayed up on the topic. That’s a good question. I was lucky enough to get two days worth of firehose from a ton of experts – from developers to engineers configuring modern DNS and even a couple of project managers on DNS projects. I’ll try to distill some of that data out for you. Where it is clearer to use a concrete example or specific terminology, as almost always that example will be of my employer or a partner. From my perspective it is best to stick to examples I know best, and from yours, simply call your vendor and ask if they have similar functionality. Massively distributed is tough if you are coming from a traditional DNS environment, because DNS alone doesn’t do it. DNS load balancing helps, but so does the concept of a Wide IP. That’s an IP that is flexible on the back end, but static on the front end. Just like when load balancing you have a single IP that directs users to multiple servers, a Wide IP is a single IP address that directs people to multiple locations. A Wide IP is a nice abstraction to actively load balance not just between servers but between sites. It also allows DNS to be simplified when dealing with those multiple sites because it can route to the most appropriate instance of an application. Today most appropriate is generally defined by geographically closest, but in some cases it can include things like “send our high-value customers to a different datacenter”. There are a ton of other issues with this type of distribution, not the least of which is database integrity and primary sourcing, but I’m going to focus on the DNS bit today, just remember that DNS is a tool to get users to your systems like a map is a tool to get customers to your business. In the end, you still have to build the destination out. DNS that supports IPv4 and IPv6 both will be mandatory for the foreseeable future, as new devices come online with IPv6 and old devices persist with IPv4. There are several ways to tackle this issue, from the obvious “leave IPv4 running and implement v6 DNS” to the less common “implement a solution that serves up both”. DNSSEC is another tough one. It adds complexity to what has always been a super-simplistic system. But it protects your corporate identity from those who would try to abuse it. That makes DNSSEC inevitable, IMO. Risk management wins over “it’s complex” almost every time. There are plenty of DNSSEC solutions out there, but at this time DNSSEC implementations do not run BIND. The update ISC is working on might change that, we’ll have to see. The ability to change what’s behind a DNS name dynamically is naturally greatly assisted by the aforementioned Wide IPs. By giving a constant IP that has multiple variable IPs behind it, adding or removing those behind the Wide IP does not suffer the latency that DNS propagation requires. Elasticity of servers servicing a given DNS name becomes real simply by the existence of Wide IPs. Keeping DNS servers synched can be painful in a dynamic environment. But if the dynamism is not in DNS address responses, but rather behind Wide IPs, this issue goes away also. The DNS servers will have the same set of Name/address pairs that require changes only when new applications are deployed (servers is the norm for local DNS, but for Wide-IP based DNS, servers can come and go behind the DNS service with only insertion into local DNS, while a new application might require a new Wide-IP and configuration behind it). Okay, this got long really quickly. I’m going to insert an image or two so that there’s a graphical depiction of what I’m talking about, then I’m going to cut it short. There’s a lot more to say, but don’t want to bore you by putting it all in a single blog. You’ll hear from me again on this topic though, guaranteed. Related Articles and Blogs F5 Friday: Infoblox and F5 Do DNS and Global Load Balancing Right. How to Have Your (VDI) Cake and Deliver it Too F5 BIG-IP Enhances VMware View 5.0 on FlexPod Let me tell you Where To Go. Carrier Grade DNS: Not your Parents DNS Audio White Paper - High-Performance DNS Services in BIG-IP ... Enhanced DNS Services: For Administrators, Managers and Marketers The End of DNS As We Know It DNS is Like Your Mom F5 Video: DNS Express—DNS Die Another Day339Views0likes0Comments